Spark-源码系列-SparkCore-Shuffle 设计-内存管理
一、概述
Map 任务在执行结束后会将数据写入磁盘,等待 reduce 任务获取。但在写入磁盘之前,Spark 可能会对 map 任务的输出在内存中进行一些排序和聚合
二、内存空间管理
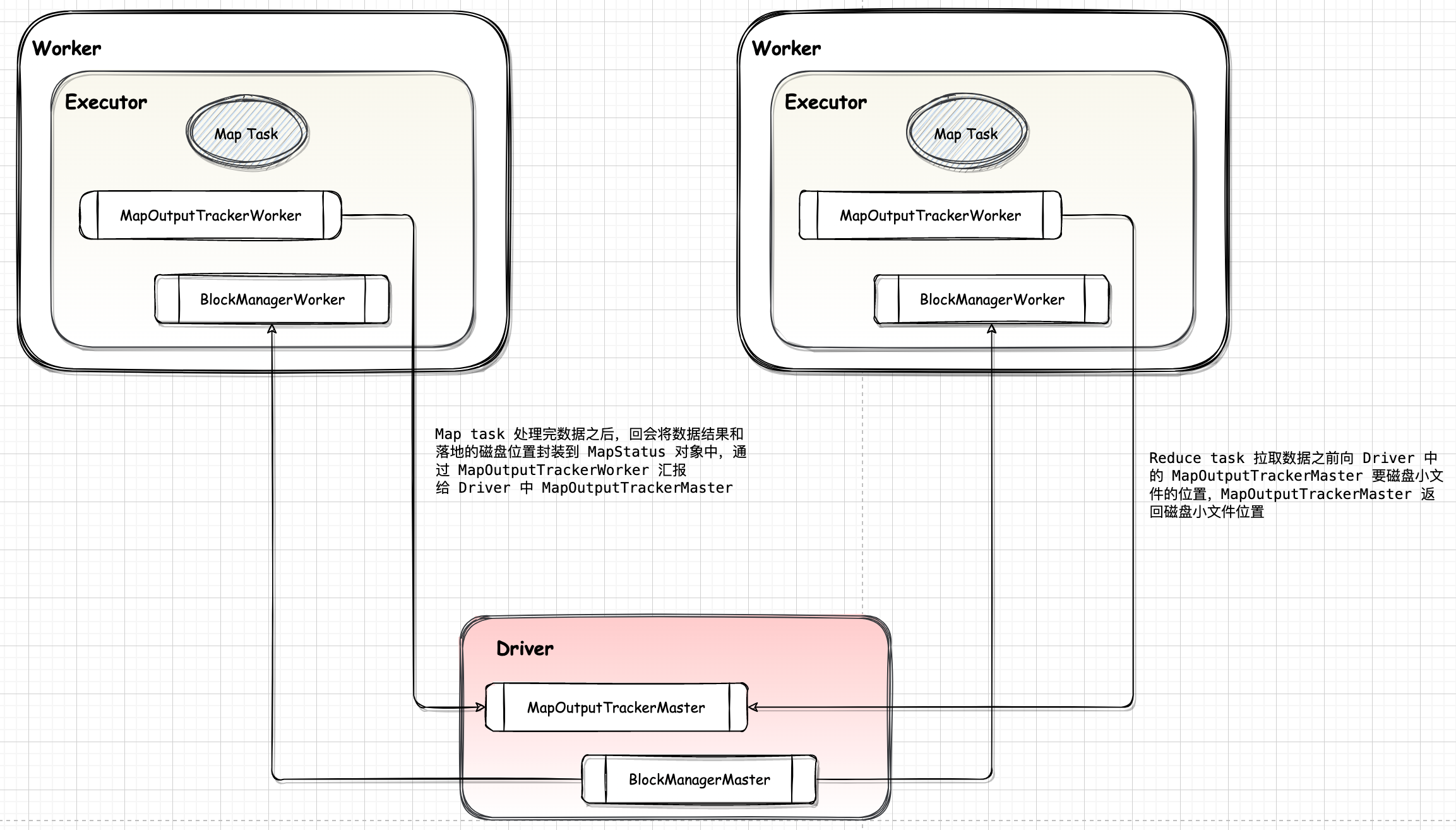
Spark 内存管理组件包括 JVM 范围内的内存管理 MemoryManager 和单个任务的内存管理 TaskMemoryManager。MemoryManager, TaskMemoryManager 和 MemoryConsumer 之前的对应关系,如下图。总体上一个 MemoryManager 对应着至少一个 TagrMemoryManager (具体由 executor-core 参数指定),而一个 TaskMemoryManager 对应着多个 MemoryConsumer(具体由任务而定)。当有多个 Task 同时在 Executor 上执行时,将会有多个 TaskMemoryManager 共享 MemoryManager 管理的内存。
https://mp.weixin.qq.com/s/QGlZTUWdst5I_aA7NBJjoA
https://baijiahao.baidu.com/s?id=1709266928641682865&wfr=spider&for=pc

2.1. 内存模型
2.1.1. 内存消费者 MemoryConsumer
抽象类 MemoryConsumer 定义了内存消费者的规范,是 TaskMemoryManager 的客户端,对应于任务中的单个运算符和数据结构。TaskMemoryManager 从 MemoryConsumer 接收内存分配请求,并向使用者发出回调,以便在内存不足时触发溢出。
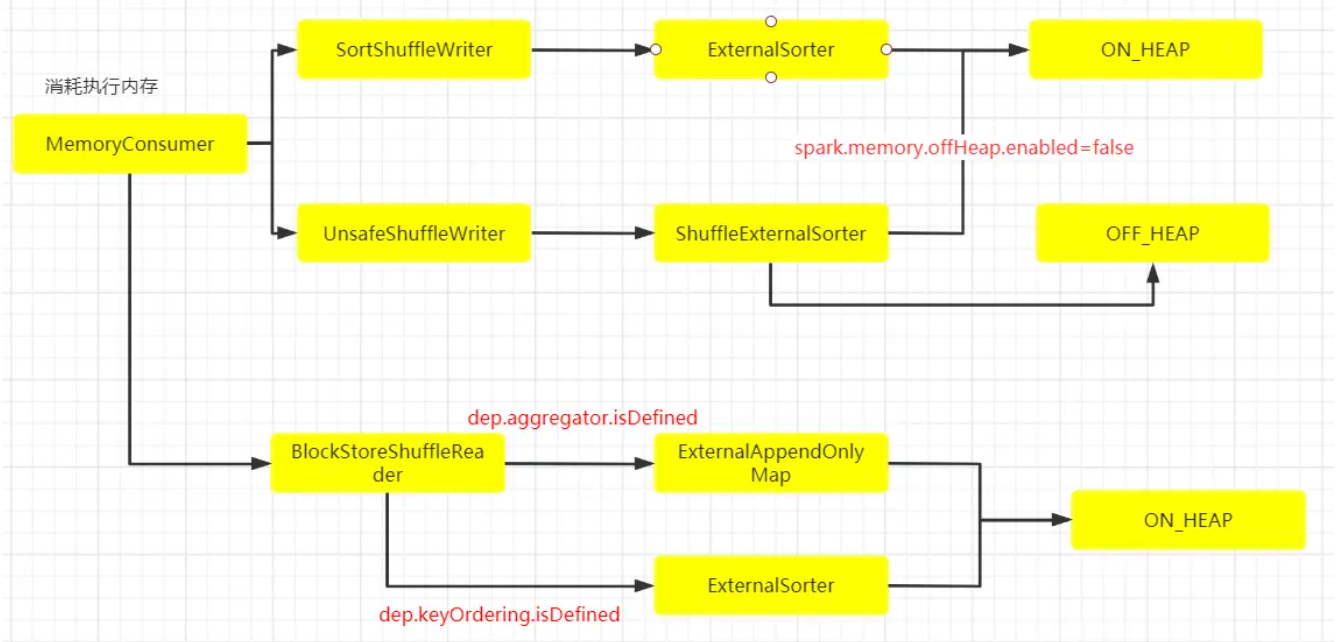
在 Spark 中,使用抽象类 MemoryConsumer 来表示需要使用内存的消费者。在这个类中定义了分配,释放以及 Spill 内存数据到磁盘的一些方法或者接口。具体的消费者可以继承 MemoryConsumer 从而实现具体的行为。 因此,在 Spark Task 执行过程中,会有各种类型不同,数量不一的具体消费者。如在 Spark Shuffle 中使用的 ExternalAppendOnlyMap, ExternalSorter 等等。
2.1.2. TaskMemoryManager
MemoryConsumer 将申请,释放相关内存的工作交由 TaskMemoryManager 来执行。当一个 Spark Task 被分配到 Executor 上运行时,会创建一个 TaskMemoryManager。在 TaskMemoryManager 执行分配内存之前,需要首先向 MemoryManager 进行申请,然后由 TaskMemoryManager 借助 MemoryAllocator 执行实际的内存分配。
TaskMemoryManger 负责管理单个任务的堆外执行内存和堆内执行内存,Spark 中 Task 的执行内存是通过 TaskMemoryManger 统一管理的,不论是ShuffleMapTask 还是 ResultTask,Spark 都会生成一个专用的 TaskMemoryManger 对象,然后通过 TaskContext 将 TaskMemoryManger 对象共享给该 task attempt 的所有 MemoryConsumer。 TaskMemoryManger 自建了一套内存页管理机制,并统一对 ON_HEAP 和 OFF_HEAP 内存进行编址,分配和释放。
2.1.3. MemoryManager
Spark 使用 MemoryManager 对存储体系和内存计算所使用的内存进行管理。Executor 中的 MemoryManager 会统一管理内存的使用。由于每个 TaskMemoryManager 在执行实际的内存分配之前,会首先向 MemoryManager 提出申请。因此 Memory Manager 会对当前进程使用内存的情况有着全局的了解。
2.2. 任务内存分配
Spark 内存管理组件包括 JVM 范围内的内存管理 MemoryManager 和单个任务的内存管理 TaskMemoryManager。
当有多个 Task 同时在 Executor 上执行时, 将会有多个 TaskMemoryManager 共享 MemoryManager 管理的内存。
那么 MemoryManager 是怎么分配的呢?答案是每个任务可以分配到的内存范围是 [1 / (2 * n), 1 / n],其中 n 是正在运行的 Task 个数。因此,多个并发运行的 Task 会使得每个 Task 可以获得的内存变小。
在 MemoryConsumer 中有 $spill$ 方法,当 MemoryConsumer 申请不到足够的内存时,可以 $spill$ 当前内存到磁盘,从而避免无节制的使用内存。但是,对于堆内内存的申请和释放实际是由 JVM 来管理的。因此,在统计堆内内存具体使用量时,考虑性能等各方面原因,Spark 目前采用的是抽样统计的方式来计算 MemoryConsumer 已经使用的内存,从而造成堆内内存的实际使用量不是特别准确。从而有可能因为不能及时 Spill 而导致 OOM。
Spark 通过 MemoryManager 提供了一个内存管理接口。它实现了在任务之间划分可用内存以及在存储和执行之间分配内存的策略。
三、聚合&排序
3.1. 概述
3.2.数据结构
https://blog.csdn.net/fengshaungme/article/details/84523666
为了提⾼聚合和排序性能,Spark 为 Shuffle Write/Read 的聚合和排序过程设计了3种数据结构,三种数据结构的基本思想: 在内存中对 Record 进⾏聚合和排序,如果存放不下,则进⾏扩容,如果还存放不下,就将数据排序后 Spill 到磁盘上,最后将磁盘和内存中的数据进⾏聚合、排序,得到最终结果。
| 数据结构类型 | 名称 | 功能 |
|---|---|---|
| 类似 HashMap + Array | PartitionedAppendOnlyMap | 用于 Map 端聚合及排序,包含 partitionId |
| 类似 HashMap + Array | ExternalAppendOnlyMap | 用于 Reduce 端聚合及排序 |
| 类似 Array | PartitionedPairBuffer | 仅用于 Map 和 Reduce 端数据排序,包含 partitionId |
3.1. AppendOnlyMap
AppendOnlyMap 是 Spark 自己实现的 HashMap,与 Java 自身的 HashMap 不同,它只能添加数据,不能 remove,同时支持在内存中对任务执行结果进行聚合运算
3.1.1. PartitionedAppendOnlyMap
https://blog.csdn.net/lidongmeng0213/article/details/109330980
https://blog.csdn.net/zhanglong_4444/article/details/118409510
3.1.2. ExternalAppendOnlyMap
继承于 AppendOnlyMap ,但是存储级别是 Memory and Disk,即在数据量达到一个阈值的时候,会把数据溢写到磁盘,达到释放内存空间,降低 OOM 的风险的作用。
3.2. PartitionedPairBuffer
四、采样和估算
Spark 在 Shuffle 阶段,给 map 任务的输出增加了缓存、聚合的数据结构。这些数据结构将使用各种执行内存,为了对这些数据结构的大小进行计算,以便于扩充大小或在没有足够内存时溢出到磁盘。
五、总结
 微信
微信 支付宝
支付宝