Flink-源码学习-架构设计
一、概述
Flink 是一个批流一体的分布式计算引擎,作为一个分布式计算引擎,必须提供面向开发人员的 API,根据业务逻辑开发 Flink 作业,作业除了包含业务逻辑外,还需要跟外部的数据存储进行交互。作业开发、测试完华后,交给 Flink 集群进行执行,同时还要让运维人员能够管理与监控 Flink。

二、集群组件
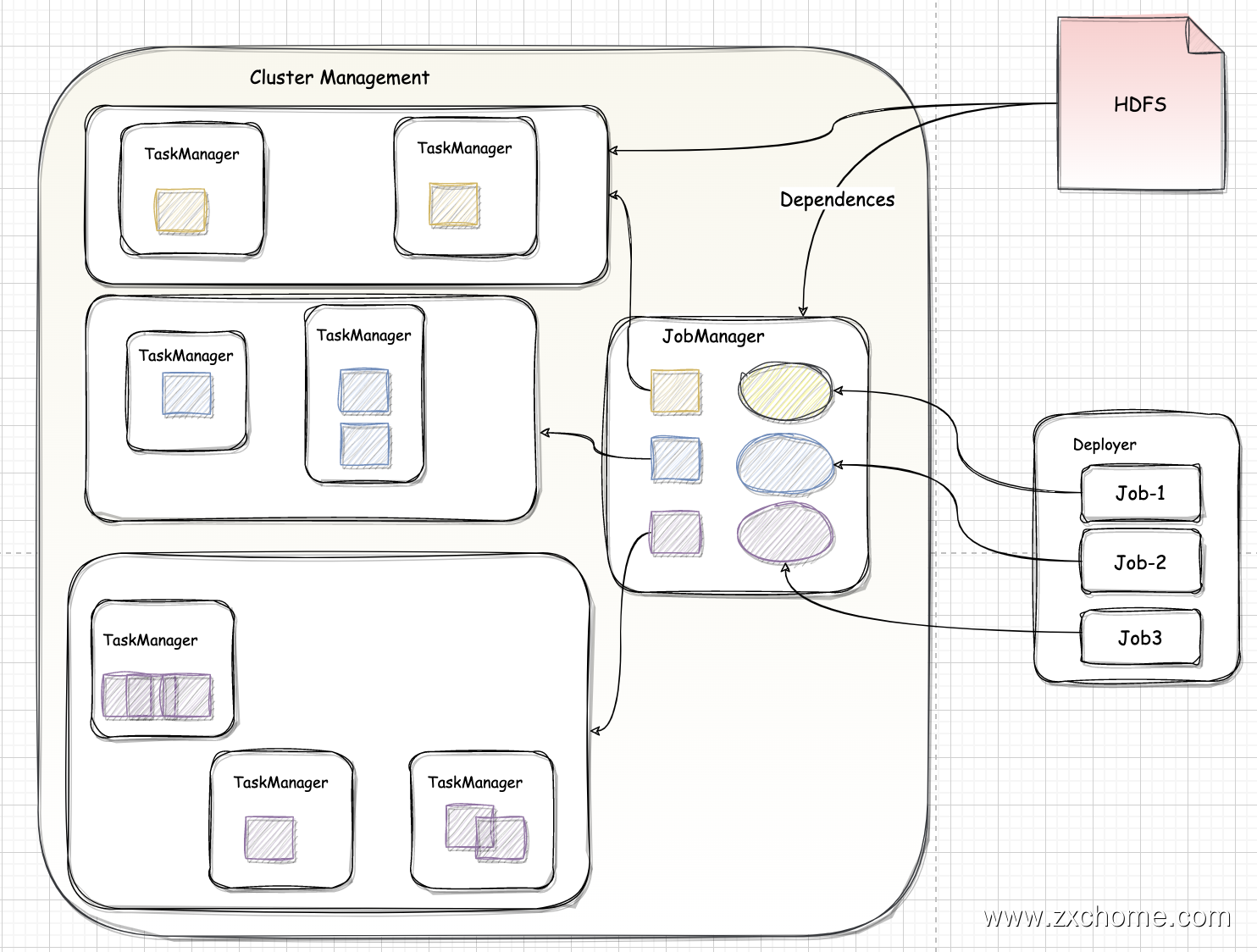
Flink 采用 Master-Slave 架构,其中 JobManager 作为集群 Master 节点,主要负责任务协调和资源分配,TaskManager 作为 slave 节点,用于执行任务。

2.1. JobManager
JobManager 相当于整个集群的 Master 节点,且整个集群有且只有一个活跃的 JobManager(在高可用场景下,可能会出现多个 JobManager;这时只有一个是正在活跃的领导 Leader 节点,其他都是 Standby 节点)。
- 负责整个集群的任务调度和资源管理。从客户端中获取提交的 Flink Job,然后根据集群中 TaskManager 上 TaskSlot 的使用情况,为提交的 Job 分配相应的 Taskslot 资源,并命令 TaskManager 启动从客户端中获取的应用。
- JobManager 和 TaskManager 之间通过 Actor 进行通信,获取任务执行的情况并通过 Actor 将应用的任务执行情况发送给客户端。
- 在任务执行的过程中,Flink JobManager 会触发 Checkpoint 操作,每个 TaskManager 节点 收到 Checkpoint 触发指令后,完成 Checkpoint 操作,所有的 Checkpoint 协调过程都是在 Flink JobManager 中完成。
- 当任务完成后,Flink 会将任务执行的信息反馈给客户端,并且释放掉 TaskManager 中的资源以供下一次提交任务使用。
2.2. TaskManager
TaskManager 相当于整个集群的 Slave 节点,负责具体的任务执行和对应任务在每个节点上的资源申请和管理。每一个 TaskManager 都包含了一定数量的任务槽(slots)。Slot 是资源调度的最小单位,slot 的数量限制了 TaskManager 能够并行处理的任务数量。
2.2.1. Slot
TaskManager 是实际负责执行计算的 Worker,是一个 JVM 进程,以独立的线程来执行一个 task 或多个 subtask。为了控制一个 TaskManager 能接受多少个 task,Flink 提出了 Task Slot 的概念,即 TaskManager 节点上固定大小的资源子集,TaskManager 通过管理多个 Taskslot 资源池进行对资源进行管理,多个任务之间通过 Taskslot 方式共享系统资源。
Flink 的任务运行采用多线程的方式,这和 MapReduce 多 JVM 进行的方式有很大的区别,能够提高 CPU 使用效率。
TaskManager 的一个 Slot 代表一个可用线程,避免了不同 Job 的 Task 互相竞争内存资源,但是需要注意的是,Slot 只会做内存的隔离。没有对CPU 隔离。默认情况下,Flink 允许子任务共享 Slot,即使是不同 Task 的 subtask,只要它们来自相同的 Job,这种共享模式可以有效提高资源利用率。
如图所示图中有两个 TaskManager,每个 TaskManager 有三个 Slot,这样集群的算子最大并行度那么可以达到 6,在同一个 Slot 里面可以执行 1至多个子任务。如图 source/map/keyby/window/apply 算子最大可以设置 6个并行度,sink 只设置了 1个并行度。
每个 Flink TaskManager 在集群中提供 Slot,Slot 的数量通常与每个 TaskManager 的可用 CPU 内核数成比例(一般情况下 Slot 个数是每个 TaskManager 的 CPU 核数)
Flink 配置文件中设置的一个 TaskManager 默认的 Slot 是 1, taskmanager.numberofTaskslots:1 该参数可以根据实际情况做修改。
2.2.2. Parallelism 并行度
Slot 是指 TaskManager 最大能并发执行的能力,parallelism 是指 TaskManager 实际使用的并发能力
三、运行时架构
3.1. 运行时组件

3.1.1. JobManager 运行时组件
- 资源管理器(ResourceManager) ResourceManager 主要负责资源的分配和管理。
Flink 的 ResourceManager,针对不同的环境和资源管理平台(比如 Standalone 部署,或者 YARN),有不同的具体实现:在 Flink 集群中只有一个所谓”资源”,即 TaskManager 的任务槽 (task slots)
注意把 Flink 内置的 ResourceManager 和 其他资源管理平台(比如 YARN)的 ResourceManager 区分开
- Standalone
Standalone 模式下 ResourceManager 只能分发可用 TaskManager 的任务槽 slot,不能单独启动新 TaskManager,即 Standalone 只有 Session 模式。 - 第三方资源管理平台(YARN、 Kubernetes)在第三方资源管理平台(YARN、Kubernetes)不受此限制。当新作业申请资源时,ResourceManager 会将有空闲 slot 位的 TaskManager 分配给 JobMaster。如果 ResourceManager 没有足够的 slot,它还可以向第三方资源管理平台(YARN、Kubernetes)发起会话,请求提供启动 TaskManager 进程的容器。另外,ResourceManager 还负责停掉空闲的 TaskManager,释放计算资源。
- Standalone
- 分发器(Dispatcher)
Dispatcher 是 Rest 接口,不负责实际的调度、执行方面的工作,当收到 JobGraph 后,为作业创建一个 JobMaster,将工作交给JobMaster(负责作业调度、管理作业和 Task 的生命周期),构建 ExecutionGraph(JobGraph 的并行化版本,调度层最核心的数据结构)Dispatcher 也会启动一个 Web UI,用来方便地展示和监控作 业执行的信息。
Dispatcher 在架构中并不是必需的,在不同的部署模式干可能会被忽略掉。
3. WebMonitorEndpoint
WebMonitorEndpoint 负责接收客户端提交的各种 Restful 请求,包括客户端通过 Flink 脚本提交以及在 Flink UI 中发出的请求,最终这些请求都会被 WebMonitorEndpoint 接收,通过 WebMonitorEndpoint 提供的 Restful 接口还可以查看集群整体监控信息、获取任务执行状态。
- JobMaster
JobMaster 是 JobManager 中最核心的组件,负责处理单独的作业(Job)。所以 JobMaster 和具体的 Job 是一一对应的,多个 Job 可以同时运行在一个 Flink 集群中。
需要注意在早期版本的 Flink 中,没有 JobMaster 的概念;而 JobManager 的概念范围较小,实际指的就是现在 JobMaster。
在作业提交时,JobMaster 会先接收客户端提交作业: 包括 jar 包,数据流图(dataflow graph),和作业图(JobGraph)
JobMaster 把 JobGraph 转换成 ExecutionGraph
JobMaster 会向资源管理器(ResourceManager)发出请求,申请执行任务必要的资源。一旦它获取到了足够的资源、就会将ExecutionGraph 分发到真正运行它们的 TaskManager 上。
运行过程中,JobMaster 会负责所有需要中央协调的操作,比如检查点(checkpoints) 的协调。
3.1.2. TaskManager 运行时组件
TaskExecutor 是 TaskManger 的具体实现,类似于 Spark 中 Executor 组件。TaskExecutor 需要向 ResourceManager 报告 slot 的状态(这样 ResourceManager 可以得知所有 slot 的分配情况)。
TaskExecutor 的基本工作及其对应的组件、接口:
- ResourceManagerLeaderListener 主要向 ResourceManager 上报所有 slot 资源的状态
- JobLeaderListenerImpl 向对应的 JobMaster 提供其对应 jobld 的 slot 的状态
- TaskSlotTable 负责管理当前 TaskExecutor 上的所有 slot
- 心跳管理(汇报slot)JobManagerHeartbeatListener、 ResourceManagerHeartbeatListener
- TaskExecutorGateway 负责任务的基本管理、checkpoint管理等
3.2. 部署模式
3.2.1. Session 模式
Session 模式会初始化一个 Flink 集群,此后提交的任务共享这个 Flink 集群资源,且该 Flink 集群会常驻,除非手动停止。在 Session 模式下,WebMonitorEndpoint、Dispatcher、ResourceManager 组件会在 JobManager 启动时会一起启动。

3.2.2. Per-Job
和 Session 模式共享同一个 Flink 集群不同,Per-Job 模式每次提交任务都会创建一个新的 Flink 集群,任务之间相互独立,当其中一个任务发生错误时只会使自己集群的 TaskManager 挂掉,不影响其他任务执行,且每个运行任务的 Flink 集群可以独立进行配置。任务执行结束后创建的 Flink 集群也会消失,其产生的中间文件或缓存的文件将会被清理。
考虑到集群的资源隔离情况,一般生产上的任务都会选择 Per-Job 模式。

3.2.3. Application 模式
无论是 Session 模式 还是 Per-Job 模式,其 main() 方法都是在客户端执行来获取 Flink 运行时所需的依赖项,并生成 JobGraph,提交到集群的操作都会在实时平台所在的机器上执行,那么将会给服务器造成很大的压力。尤其在大量用户共享客户端时,问题更加突出。其次两种模式提交任务的时候会把本地 Flink 的所有 jar 包先上传到 hdfs 上相应的临时目录,这个也会带来大量的网络的开销,所以如果任务特别多的情况下,平台的吞吐量将会直线下降。
Flink-1.11 中引入了一种新的部署模式,即 Application 模式。目前,Flink-1.11 已经可以支持基于 Yarn 和 Kubernetes 的 Application 模式。Application 模式下,用户程序的 main() 方法将在集群中而不是客户端运行。用户将程序逻辑和依赖打包进一个可执行的 jar 包里,集群的入口程序(ApplicationClusterEntryPoint) 负责调用其中的 main() 方法来生成 JobGraph。 Application 模式为每个提交的应用程序创建一个集群,该集群可以看作是在特定应用程序的作业之间共享的 session 集群,并在应用程序完成时终止。
该模式没有明显的缺点,也是目前社区主推的运行模式,适用于生产环境。
3.3. refer
 微信
微信 支付宝
支付宝