Spark-源码系列-SparkCore-Shuffle-ShuffleWrite-Writer-SortShuffleWriter
一、概述
SortShuffleWriter 实现类是用于兜底的,在 ShuffleWrite 阶段,如果不满足 UnsafeShuffleWriter、BypassMergeSortShuffleWriter 两种条件,最后代码执行 SortShuffleWriter~,支持所有的 Shuffle 场景,包括 map 端的聚合,排序等操作。
https://zhuanlan.zhihu.com/p/469752748
二、实现
SortShuffleWriter 是 ShuffleWriter 的实现类之一,提供了对 Shuffle 数据的排序功能以及聚合功能。

三、Write
SortShuffleWriter 的写入过程如图所示:

3.1. 数据写入内存缓存区
3.1.1. 聚合&排序
https://mp.weixin.qq.com/s/9zGHp3p6YJSskdsWH9PEEg
ShuffleMapTask 不断地把每个分区的数据填充到内存 buffer 中
有两种 buffer: 若需要通过 key 来进行聚合,则会使用 PartitionedAppendOnlyMap 结构; 若不需要进行聚合操作,则使用PartitionedPairBuffer。
在 buffer 中,会先按分区 Id 对记录进行排序,然后可能还会根据 key 进行排序。为了避免每个 key 多次使用分区器(partitioner),会把分区 ID 与每条记录一起存储,形如: (partitionId, K), V)。
当 buffer 达到内存上限时,就会把 buffer 的内容写入磁盘的一个临时文件中,然后释放内存资源。若需要进行聚合操作时,会先对记录按分区 Id 进行排序,然后还可能根据 key 或 key 的 hashcode 进行排序。对于每个文件,会跟踪记录每个分区有多少条数据,所以,不需要为每条数据写出分区Id。
SortShuffleWriter 的排序和聚合功能由 ExternalSorter 排序器提供支持~
创建基于 JVM 的外排器 ExternalSorter, 根据是否在 map 端进行数据合并初始化 ExternalSorter
1 | sorter = if (dep.mapSideCombine) { |
- aggregator: map/reduce-side 使用的聚合器 aggregator
- partitioner: 对 shuffle 的输出,使用哪种 partitioner 对数据做分区,如 hashPartitioner 或者 rangePartitioner
- ordering: 根据哪个 key 做排序
- serializer: 序列化,如果没有显示指定,默认使用 spark.serializer 参数值
3.1.2. 数据写入 Buffer
1 | sorter.insertAll(records) |
3.2. 合并临时文件
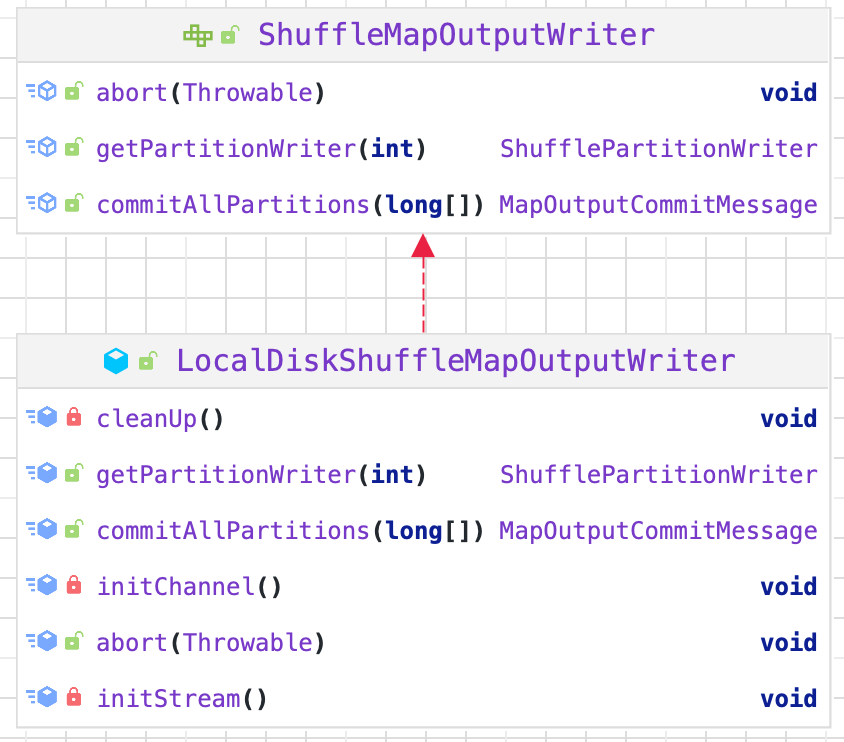
3.2.1. 初始化 ShuffleMapOutputWriter
1 | val mapOutputWriter = shuffleExecutorComponents.createMapOutputWriter( |
LocalDiskShuffleMapOutputWriter 将输出的所有分区文件合并成一个文件
3.2.2. 写入临时文件
buffer 到达上限时,创建并写入临时文件
1 | sorter.writePartitionedMapOutput(dep.shuffleId, mapId, mapOutputWriter) |
3.2.3. 合并文件
1 | partitionLengths = mapOutputWriter.commitAllPartitions(sorter.getChecksums).getPartitionLengths |
3.3. 初始化 MapStatus
1 | mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths, mapId) |
 微信
微信 支付宝
支付宝