
Spark-源码系列-SparkCore-Shuffle-ShuffleRead
一、概述
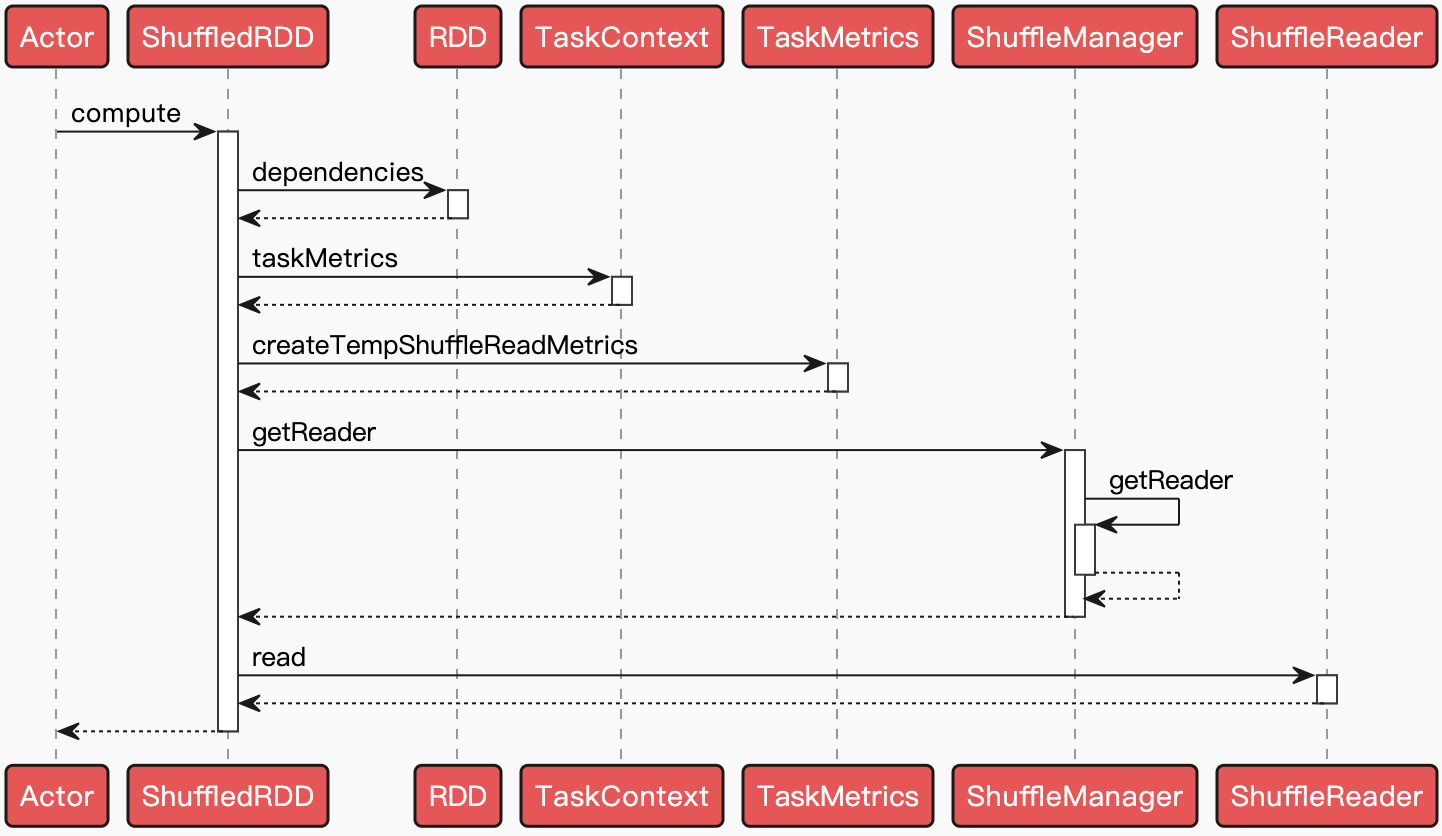
Spark ShuffleRead 主要经历从获取数据,序列化流,添加指标统计,可能的聚合 (Aggregation) 计算以及排序等过程。当 Map 任务相关 Stage 的任务都执行完毕后,会唤起下游 Stage 的提交及任务的执行。ShuffleMapTask 计算过程最终会落实到 $ShuffledRDD.compute()$ 方法~
1 | override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = { |
二、获取 Reader
通过调用 ShuffleManager 的 $getReader()$ 方法,获取到 ShuffleReader,Spark 2.x 之后 ShuffleReader 的实现只有 BlockStoreShuffleReader,然后调用 $BlockStoreShuffleReader.read()$ 方法进行读取~
引用本站文章
Spark-源码系列-SparkCore-Shuffle-Shuffle 管理器
Joker
三、Read
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Joker!
 微信
微信 支付宝
支付宝
相关推荐

评论
ValineTwikoo





