Spark-源码系列-SparkCore-Shuffle-Shuffle 管理器-ShuffleReader-BlockStoreShuffleReader
一、概述
https://blog.csdn.net/u011239443/article/details/56843264
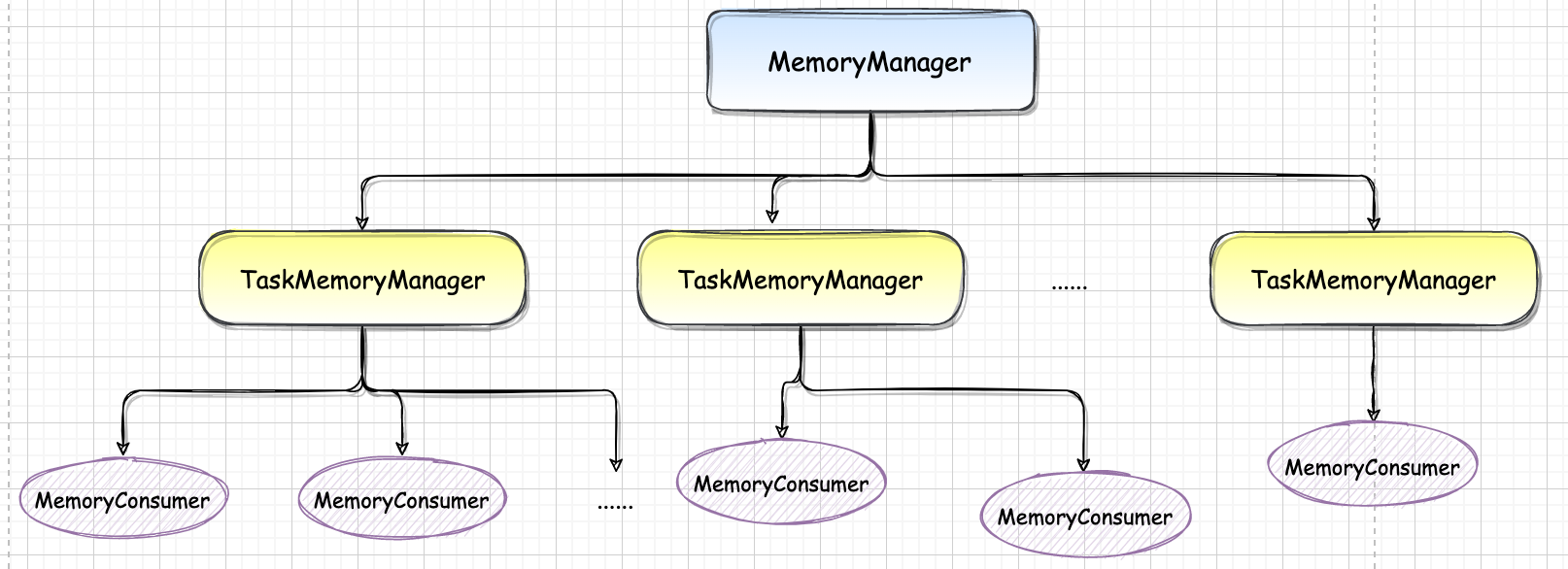
ShuffleReader 实现了下游 Task 如何读取上游 ShuffleMapTask的Shuffle 输出的逻辑,通过 MapOutputTracker 获得数据的位置信息,如果数据在本地则调用BlockManager 的 $getBlockData()$ 读取本地数据。
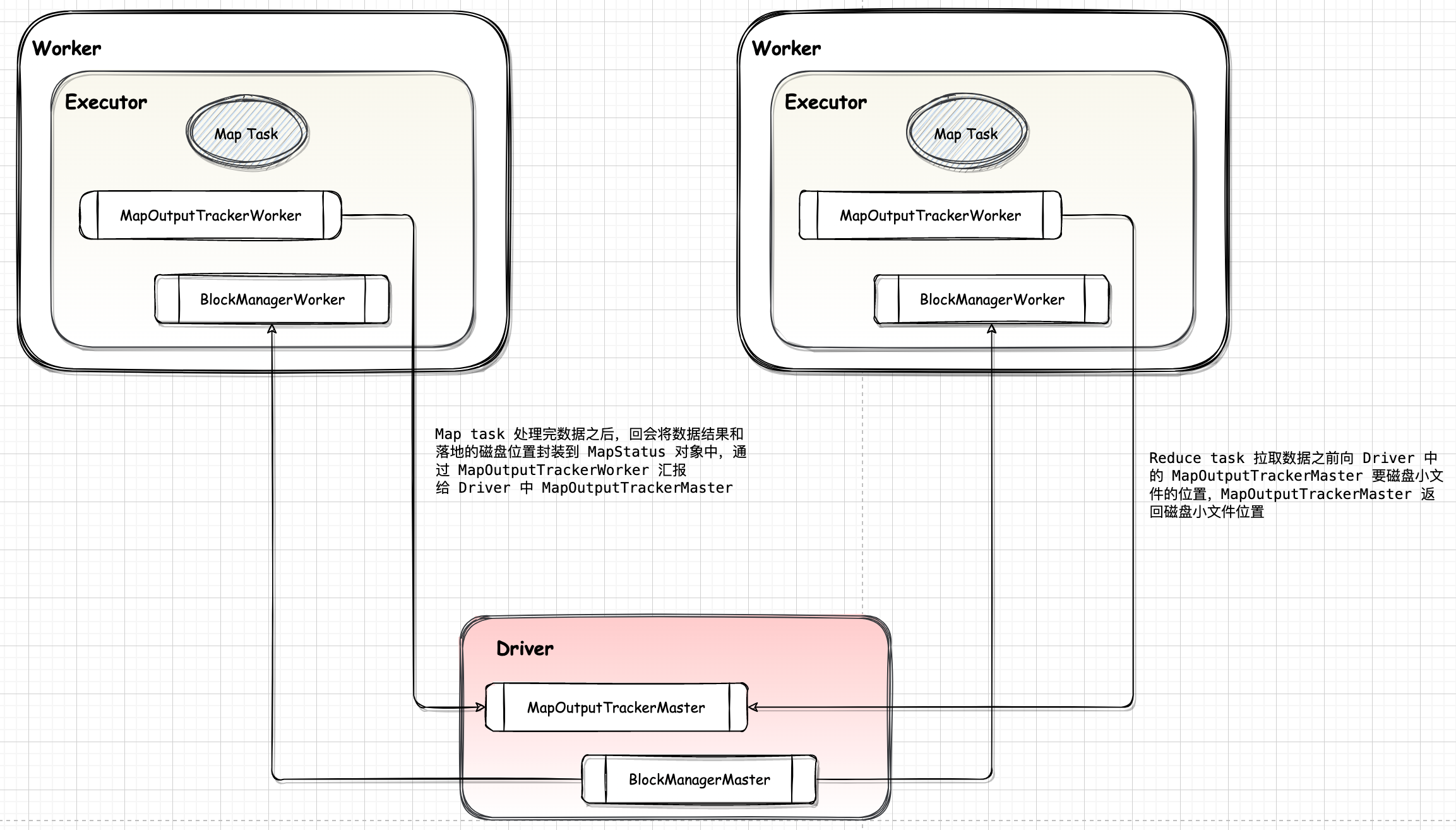
Shuffle Read 的整体架构如图所示:
$ShuffledRDD.compute()$ 开始~
1 | override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = { |
2.1. 获取 ShuffleReader
通过调用 ShuffleManager 的 $getReader()$ 方法,获取到 ShuffleReader,Spark 2.x 之后 ShuffleReader 的实现只有 BlockStoreShuffleReader,然后调用 $BlockStoreShuffleReader.read()$ 方法进行读取~
2.2. 读取数据
$BlockStoreShuffleReader.read()$
2.2.1. 初始化 ShuffleBlockFetcherIterator
获取一个包装的迭代器 ShuffleBlockFetcherIterator,它迭代的元素是blockId和这个block对应的读取流,很显然这个类就是实现reduce阶段数据读取的关键
2.2.2. 将原始读取流转换成反序列化后的迭代器
2.2.3. 将迭代器转换成能够统计度量值的迭代器,这一系列的转换和java中对于流的各种装饰器很类似
2.2.4. 中断器
将迭代器包装成能够相应中断的迭代器。每读一条数据就会检查一下任务有没有被杀死,这种做法是为了尽量及时地响应杀死任务的请求,比如从driver端发来杀死任务的消息。
2.2.5. 聚合
利用聚合器对结果进行聚合。这里再次利用了AppendonlyMap这个数据结构,前面shuffle写阶段也用到这个数据结构,它的内部是一个以数组作为底层数据结构的,以线性探测法线性的hash表。
2.2.6. 排序
最后对结果进行排序。
$BlockStoreShuffleFetcher.fetch()$ 会获得数据,它首先会通过 $MapOutputTracker.getServerStatuses()$ 来获得数据的meta信息,这个过程有可能需要向org.apache.spark.MapOutputTrackerMasterActor 发送读请求,这个读请求是在org.apache.spark.MapOutputTracker#askTracker发出的。在获得了数据的meta信息后,它会将这些数据存入Seq[(BlockManagerId,Seq[(BlockId, Long)])]中,然后调用org.apache.spark.storage.ShuffleBlockFetcherIterator最终发起请求。ShuffleBlockFetcherIterator根据数据的本地性原则进行数据获取。如果数据在本地,那么会调用org.apache.spark.storage.BlockManager#getBlockData进行本地数据块的读取。
https://mp.weixin.qq.com/s/i0JmbjNvG2jitkpGLKyGJg
二、实现
目前 ShuffleReader 只有一种实现 BlockStoreShuffleReader,BlockStoresShuffleReader 用于 Shuffle 执行过程中,reduce 任务从其他节点的 Block 文件中读取由起始分区(startPartition)和结束分区(endPartition)指定范围内的数据。
ShuffleBlockFetcherIterator
ShuffleBlockFetcherIterator 是用于获取多个 Block 的迭代器。如果 Block 在本地,那么从本地的 BlockManager 获取;如果 Block 在远端,那么通过 ShuffleClient 请求远端节点上的 BlockTransferService 获取。
2.1.3. 获取数据解析 ShuffleBlockResolver
特质 ShuffleBlockResolver 定义了对 Shuffle Block 进行解析的规范,包括获取 Shuffle 数据文件、获取 Shuffle 索引文件、删除指定的 Shuffle 数据文件和索引文件、生成Shuffle 索引文件、获取 Shuffle 块的数据等。
- IndexShuffleBlockResolver
2.2. 实现
2.2.1. SortShuffleManager
SortShuffleManager 管理基于排序的 Shuffle,输入的记录按照目标分区 ID 排序,然后输出到一个单独的 map 输出文件中。reduce 为了读出 map 输出,需要获取 map 输出文件的连续内容。当 map 的输出数据太大已经不适合放在内存中时,排序后的输出子集将被溢出到文件中,这些磁盘上的文件将被合并生成最终的输出文件。
 微信
微信 支付宝
支付宝