Spark-源码系列-SparkCore-Shuffle-外部排序器
一、概述
Spark 中的外部排序器用于对 map 任务的输出数据在 map 端或 reduce 端进行排序。
二、实现
Spark 中有两个外部排序器,分别是 ExternalSorter 和 ShuffleExternalSorter
2.1. ExternalSorter
ExternalSorter 是 SortShuffleManager 的底层组件,它提供了很多功能,包括将 map 任务的输出存储到 JVM 的堆中,如果指定了聚合函数,则还会对数据进行聚合;使用分区计算器首先将 Key 分组到各个分区中,然后使用自定义比较器对每个分区中的键进行可选的排序;可以将每个分区输出到单个文件的不同字节范围中,便于 reduce 端的 Shuffle 获取。
https://www.zhihu.com/question/264364010/answer/2514170889?utm_id=0
2.1.1. 设计
属性
方法
map 端输出的缓存处理: $insertAll()$
map 任务在执行结束后会将数据写入磁盘,等待 reduce 任务获取。但在写入磁盘之前,Spark 可能会对 map 任务的输出在内存中进行一些排序和聚合。ExternalSorter 的 $insertAll()$ 方法是这一过程的入口。
如果用户指定了聚合器,则执行如下操作:
- 获取聚合器的 $mergeValue$ 函数: 用于将新的 value 合并到聚合的结果中
- 获取聚合器的 $createCombiner$ 函数(此函数用于创建聚合的初始值)。
- 定义偏函数 $update$: 是当有新的 value 时(即
hadValue为 true),调用 $mergeValue$ 函数将新的 value 合并到之前聚合的结果中,否则说明刚刚开始聚合,此时调用 $createCombiner$ 函数以 value 作为聚合的初始值。 - 迭代输入的记录,首先调用父类 Spillable 的 $addElementsRead$ 方法增加已经读取的元素数,然后对每个
scala.Product2[K, V]的 key通过调用 $getPartition$ 方法计算分区索引 (ID),并将分区索引与 key 作为调用 AppendOnlyMap 的 $changeValue$ 方法的参数 key,以偏函数 $update$ 作为 $changeValue$ 方法的参数updateFunc,对由分区索引与 key 组成的对偶进行聚合。最后调用 $maybeSpillCollection$ 方法进行可能的磁盘溢出。
如果用户没有指定聚合器,则对迭代器中的记录进行迭代,并在每次迭代过程中执行如下操作:
- 调用父类 Spillable 的 $addElementsRead$ 方法增加已经读取的元素数。
- 对每个
scala.Product2[K, V]的 key 通过调用 $getPartition$ 方法计算分区索引(ID),并将分区索引、key 及 value 作为调用PartitionedPairBuffer 的 $insert$ 方法的参数。 - 调用 $maybeSpillCollection$ 方法进行可能的磁盘溢出。
缓存溢出: $maybeSpillCollection()$
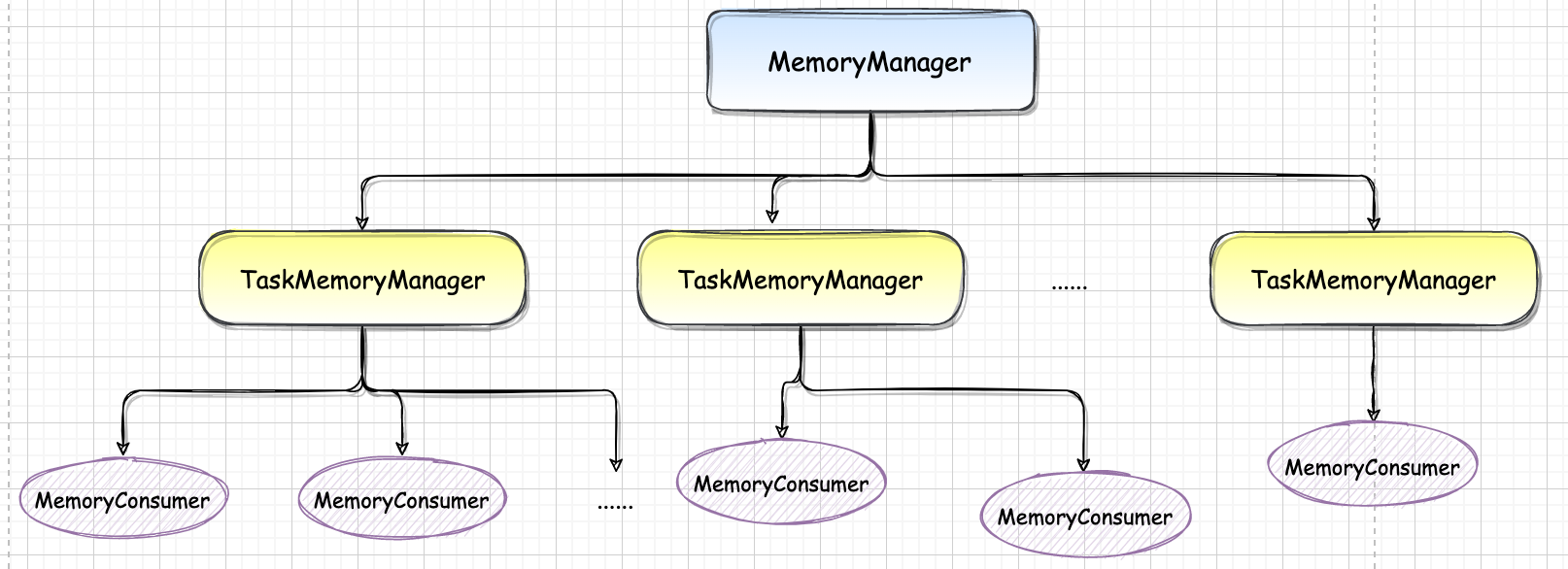
ExternalSorter 使用了 AppendOnlyMap 和 PartitionedPairBuffer
ExternalSorter 的 map 属性的类型为
PartitionedAppendOnlyMap[K, C], buffer 属性的类型为PartitionedPairBuffer[K, C]。大数据场景下,数据全部都放入内存很容易引起系统的 OOM 问题。另一方面,map 任务的输出需要写入磁盘,磁盘写入频率过高会因为大量的磁盘 I/O 降低效率,那么何时才应该将内存中的数据写入到磁盘呢🤔️?
Spark 为了解决这两个问题,提供了$maybeSpillCollection()$ 方法,以判断何时将内存中的数据写入磁盘。
- 如果 ExternalSorter 正在使用的数据结构是 PartitionedAppendOnlyMap,对 PartitionedAppendOnlyMap 的大小进行估算。调用$maybeSpill$ 方法时,如果的确将 PartitionedAppendOnlyMap中 的数据溢出到了磁盘上,那么重新创建 PartitionedAppendOnlyMap。
- 如果 ExternalSorter 正在使用的数据结构是 PartitionedPairBuffer,对 PartitionedPairBuffer 的大小进行估算。调用 $maybeSpill$ 方法时,如果的确将 PartitionedPairBuffer 中的数据溢出到了磁盘上,那么重新创建 PartitionedPairBuffer。
- 如果估算的大小超过了 ExternalSorter 已经使用的内存大小的峰值
_peakMemoryUsedBytes,那么将 ExternalSorter 的_peakMemoryUsedBytes修改为估算的大小。
$maybeSpill()$
$maybeSpill$ 方法用于将 PartitionedAppendOnlyMap 或 PartitionedPairBuffer 底层的数据溢出到磁盘
如果当前集合已经读取的元素数是32的倍数,并且集合当前的内存大小(current-Memory) 大于等于 myMemoryThreshold,那么执行以下操作:
- 调用 $acquireMemory$ 方法,为当前任务尝试获取
2 * currentMemory - myMemory - Threshold大小的内存,并获得实际获得的内存大小granted - 将 granted 累加到 myMemoryThreshold
- 判断是否应该进行溢出,即 currentMemory 是否大于等于 myMemoryThreshold。如果 currentMemory 还是大于等于 myMemoryThreshold,说明TaskMemoryManager 已经没有多余的内存可以分配了,此时应该进行溢出。
- 调用 $acquireMemory$ 方法,为当前任务尝试获取
如果需要溢出或者
_elementsRead大于 numElementsForceSpillThreshold,那就需要溢出。溢出执行的操作如下:- 将
_spillCount加一 - 调用 $spill$ 方法将集合中的数据溢出到磁盘。
- 溢出后处理,包括已读取元素数(
_elementsRead)归零,已溢出内存字节数(_memoryBytesSpilled),增加当前集合的大小 currentMemory,释放 ExternalSorter 占用的内存。
- 将
返回是否进行了溢出
map 端输出持久化: $writePartitionedFile()$
数据仅仅存放在内存中,存在着丢失的风险。ExternalSorter 的 $writePartitionedFile$ 方法用于持久化计算结果。
2.2. ShuffleExternalSorter
ShuffleExternalSorter 是专门用于对 Shuffle 数据进行排序的外部排序器,用于将 map 任务的输出存储到 Tungsten 中;在记录超过限制时,将数据溢出到磁盘。
与 ExternalSorter 不同,ShuffleExternalSorter 本身并没有实现数据的持久化功能,具体的持久化将由 ShuffleExternalSorter 的调用者UnsafeShuffleWriter 来实现。
 微信
微信 支付宝
支付宝