Spark-源码系列-SparkCore-Shuffle 设计
一、概述
Spark 在 DAG 调度阶段会将一个 Job 划分为多个 Stage,上游 Stage 做 Map 工作,下游 Stage 做 Reduce 工作,其本质上还是MapReduce 计算框架。Shuffle 是连接 map 和 reduce 之间的桥梁,它将 map 的输出对应到 reduce 输入中,涉及到序列化反序列化、跨节点网络 I/O 以及磁盘读写 I/O 等,Shuffle 的性能高低直接影响了整个程序的性能和吞吐量。
https://mp.weixin.qq.com/s/cf4JUeB-JU0cLgn04ng3og
二、Shuffle 计算
2.1. 触发 shuffle
2.1.1. 可能导致 shuffle 算子
在 Spark 作业中当父 RDD 与子 RDD 的分区对应关系为多对多或者一对多的情況下会发生宽依赖 ShuffleDependency,也即一个父 RDD 的分区需要分发到多个子 RDD 所在的任务中去执行,这种情况会涉及数据的重新分布,产生了 Shuffle 操作。
2.2. shuffle 执行
一个分区计算完成的数据,需要被多个分区拉取使用时。就会产生 Shuffle 操作,会涉及跨主机拉取数据,需要输入流和输出流,产生 ShuffleRead 和 ShuffleWrite。

2.2.1. ShuffleWrite
每个 MapTask 将数据写入内存缓冲中,当内存缓冲填满之后将数据溢写到磁盘文件中去,在溢写过程中,将 key 经过 hash 之后相同的数据写入同一个磁盘文件中,而每一个磁盘文件都只属于下游 stage 的一个 task。
2.2.2. ShuffleRead
stage 的每一个 task 将上一个 stage 的计算结果中的所有相同 key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行 key 的聚合或连接等操作。
Shuffle read 阶段的拉取过程是一边拉取一边进行聚合的。每个 shuffle read task 都会有一个自己的 buffer 缓冲,每次都只能拉取与 buffer 缓冲相同大小的数据,然后在内存进行聚合等操作。聚合完一批数据后,再拉取下一批数据,直到最后将所有数据到拉取完,并得到最终的结果。
2.3. Shuffle 组件
https://mp.weixin.qq.com/s/cf4JUeB-JU0cLgn04ng3og
2.3.1. ShuffleWriter
Shuffle 操作触发后,执行 ShuffleMapTask 实现的 $runTask()$ 方法,根据 rdd、 dependency、mapId 等信息调用 $ShuffleWriteProcessor.write()$ 方法执行 Shuffle 数据的写入。
https://www.bilibili.com/read/cv22076701/
2.3.2. ShuffleReader
在 Shuffle 的 Map 阶段(Shuffle Write 阶段)完成了数据的溢写和合并,接下来进入 Shuffle 的 Reduce 阶段(Shuffle read 阶段),stage 的每一个 task 将上一个 stage 的计算结果中的所有相同 key,从各个节点上通过网络都拉取到自己所在的节点上,然后进行 key 的聚合或连接等操作。
2.3.3. ShuffleHandle
保存了 ShuffleManger 的相关信息,可以通过它把 ShuffleManager 的信息传递给 Task
http://www.hzhcontrols.com/new-935034.html
2.3.4. ShuffleBlockResolver
通过该接口的实现来查找 shuffle 的数据块。
三、Shuffle 管理器
ShuffleManager 定义了创建 ShuffleWriter 和 ShuffleReader 的接口。自 Spark 2.0 以来,SortShuffleManager 一直是 ShuffleManager trait 的唯一实现
旧的基于 hash 的 shuffle 方法可能会产生难以管理的 shuffle 文件数量,因此不再被支持。
在 map 方面,SortShuffleManager 提供了三个 ShuffleWriter: BypassMergeSortShuffleWriter、UnsafeShuffleWriter 和SortShuffleWriter。
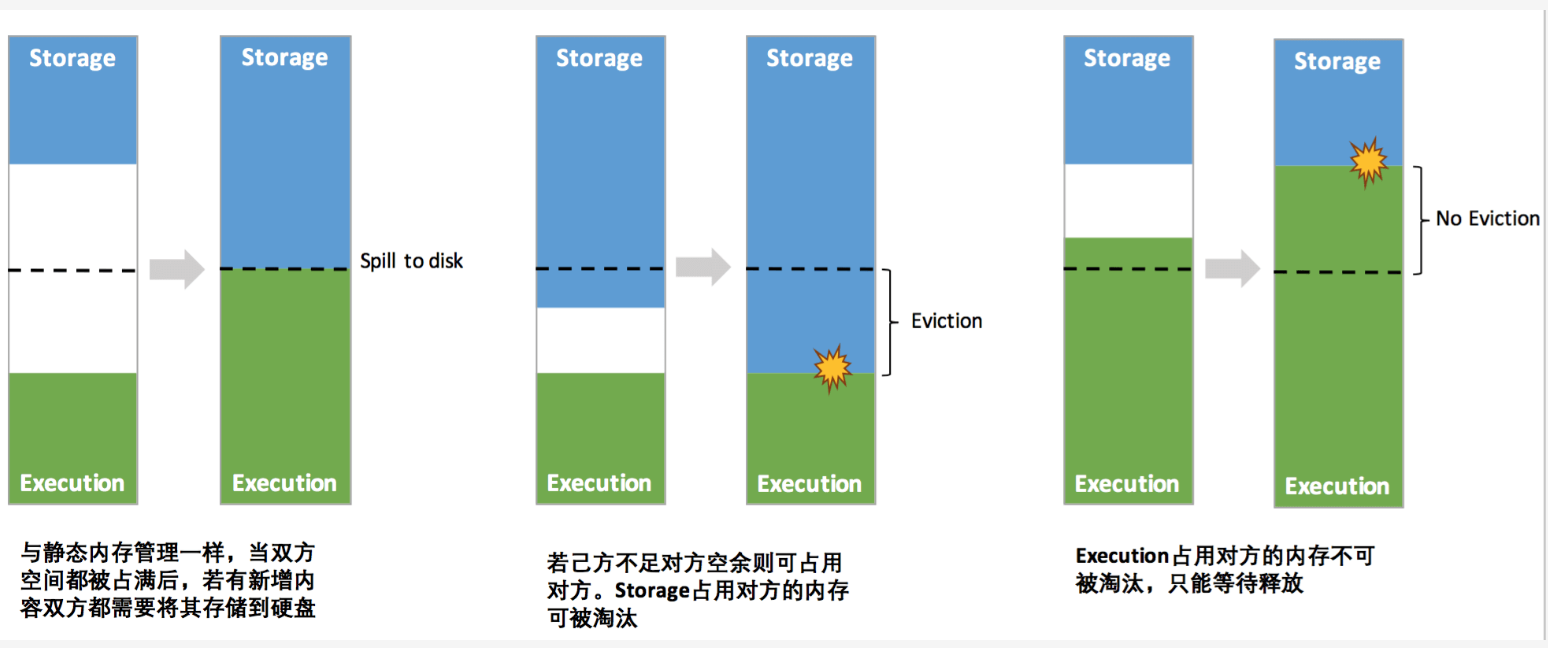
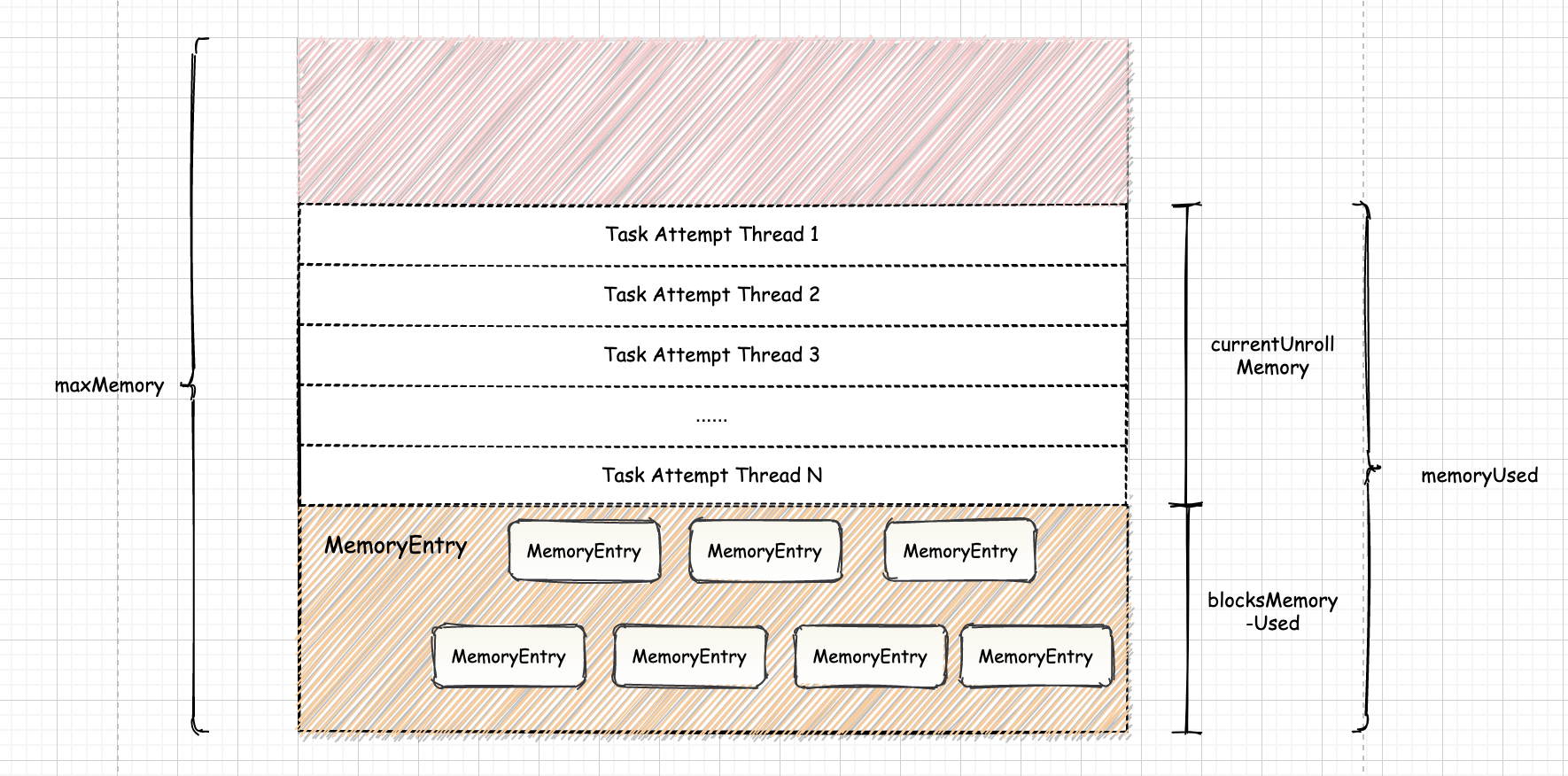
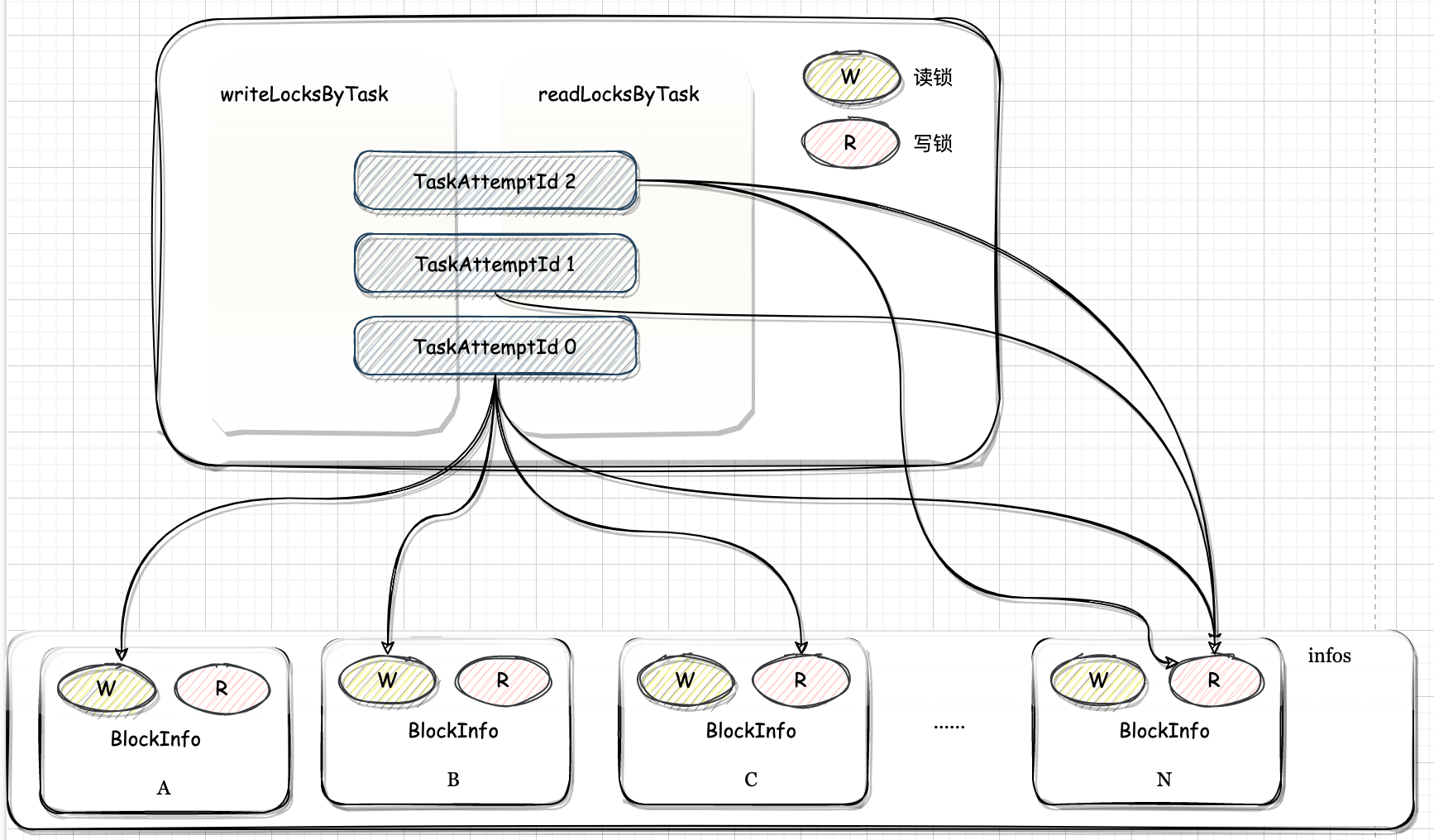
四、Shuffle 内存管理
map 任务在执行结束后会将数据写入磁盘,等待 reduce 任务获取。但在写入磁盘之前,Spark 可能会对 map 任务的输出在内存中进行一些排序和聚合。
五、优化
5.1. AQE
5.1.1.自动分区合并
5.1.2.自动倾斜处理
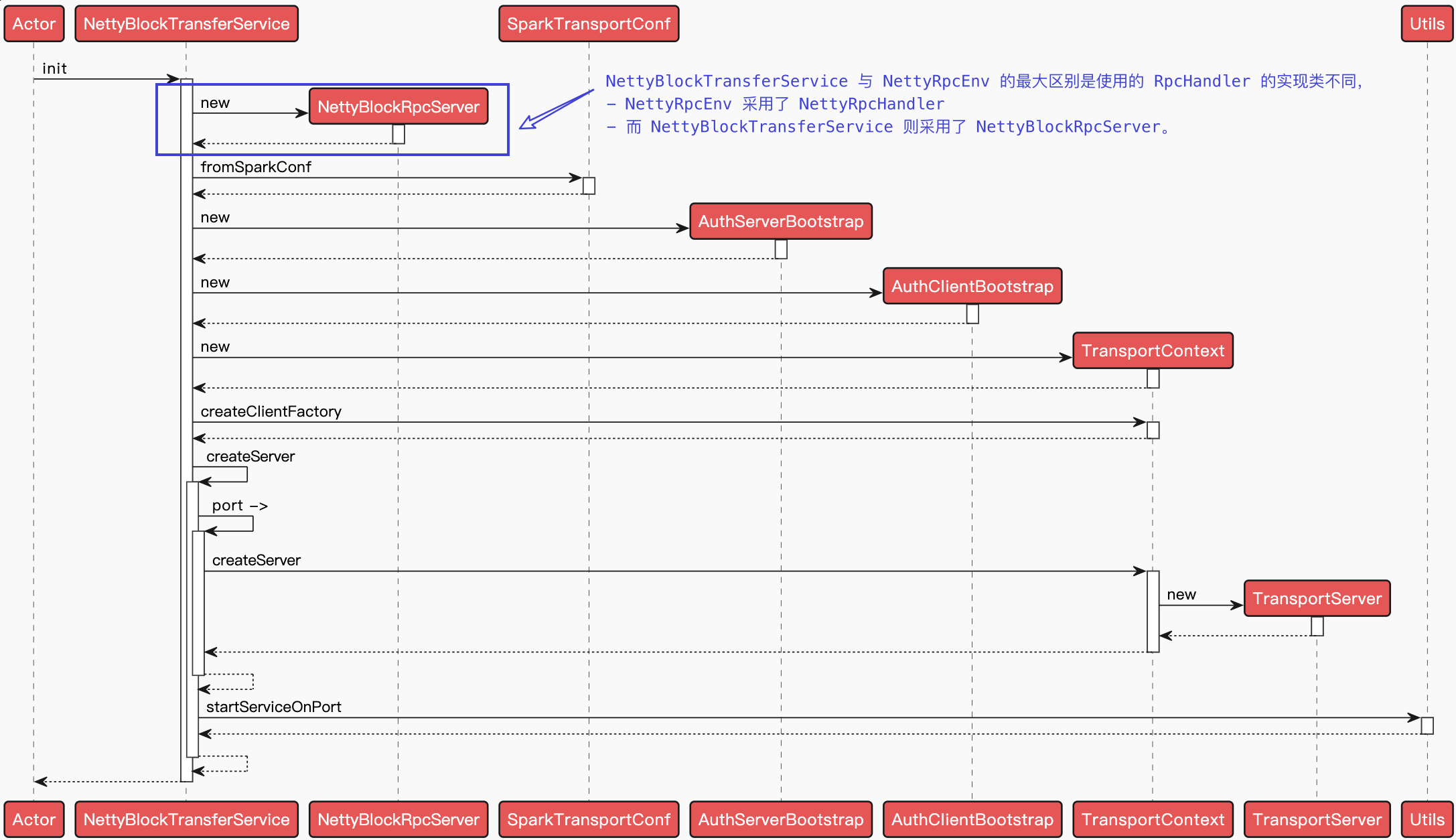
5.2. Shuffle Service
5.2.1. External Shuffle Service(ESS)
在 Spark 中,Executor 进程除了运行 task, 还要负责写 shuffle 数据,以及给其他 Executor 提供 shufle 数据。当 Executor 进程任务过重,导致 GC 而不能为其他 Executor 提供 shuffle 数据时,会影响任务运行。同时,ESS 的存在也使得,即使 executor 挂掉或者回收,都不影响其 shuffle 数据,因此只有在 ESS 开启情況下才能开启动态调整 executor 数目。
ESS 负责管理 shuffle write 端生成的 shuffle 数据,ESS 是和 yarn 一起使用的, 在 yarn 集群上的每一个 nodemanager 上面都运行一个 ESS,是一个常驻进程。一个 ESS 管理每个 nodemanager 上所有的 executor 生成的 shuffle 数据。总而言之,ESS 井不是分布式的组件,它的生命周期也不依赖于 Executor。
https://mp.weixin.qq.com/s/mmYQHuEqN3OLX9RW7BwAug
5.2.2. RSS
 微信
微信 支付宝
支付宝