Hadoop-组件-HDFS-源码学习-HDFS 集群管理
一、元数据管理
为了保证用户操作元数据高效,延迟低,NameNode 把所有的元数据都存储在内存中。内存中的元数据是最完整的,包括文件自身属性信息、文件块位置映射信息。但是内存的致命问题是,断点数据丢失,数据不会持久化。因此 NameNode 又辅佐了元数据文件(fsimage+edits)来保证元数据的安全完整。
二、数据块管理
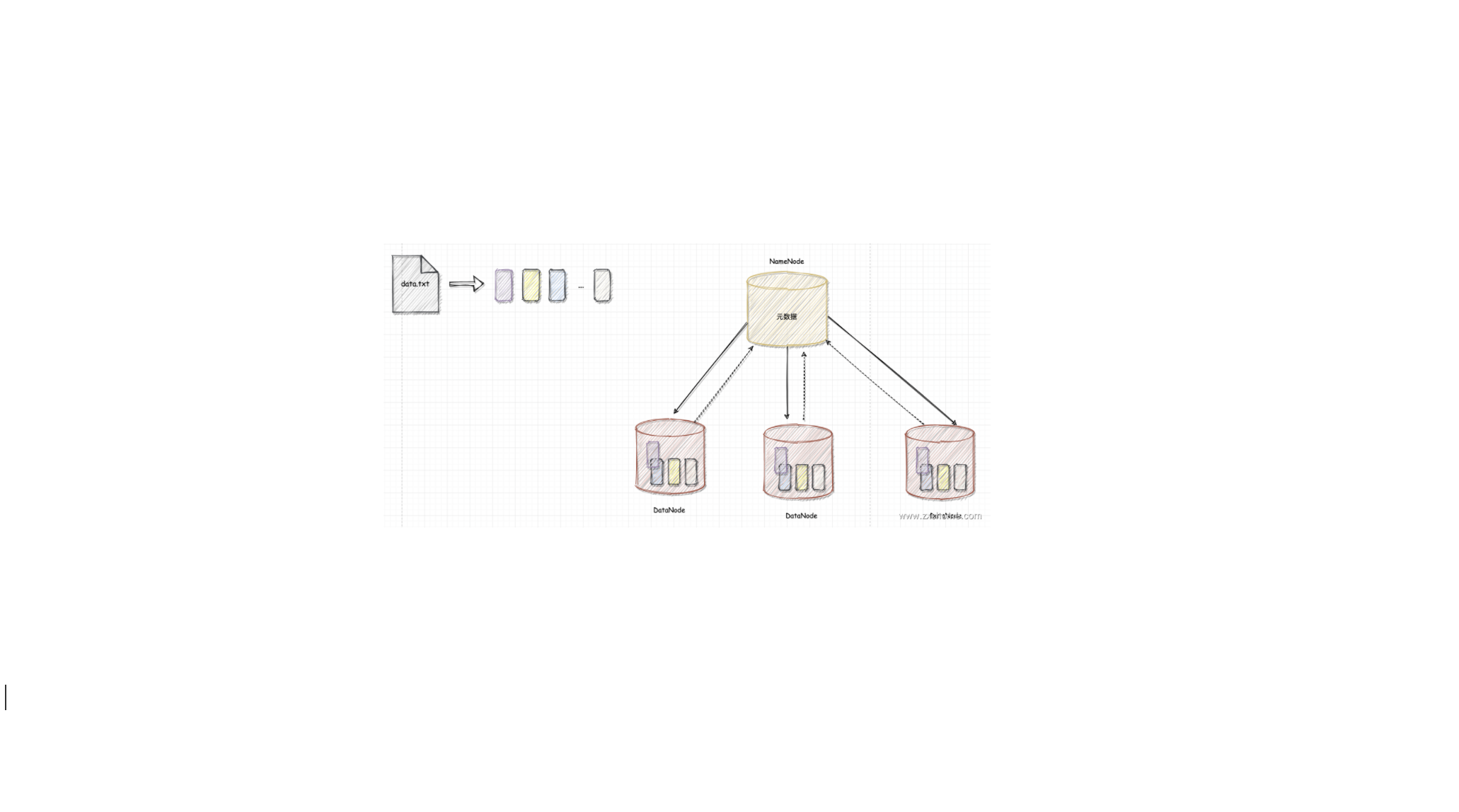
HDFS 中的数据块冗余备份在集群中的数据节点上的,Namenode 需要维护数据块与数据节点之间的对应关系。
Namenode 维护着 HDFS 中两个最重要的关系:
HDFS 文件系统的目录树以及文件的数据块索引。
数据块和数据节点的对应关系,即指定数据块的副本保存在哪些数据节点上的信息。
Namenode 定期将文件系统目录树以及文件与数据块的对应关系保存至 fsimage 文件中,然后在 Namenode 启动时读取 fsimage 文件以重建 HDFS 第 (1) 关系。这里要注意的是第 (2) 关系并不会保存至 fsimage 文件中,是由 Datanode 主动将当前 Datanode 上保存的数据块信息汇报给 Namenode,然后由 Namenode 更新内存中的数据,以维护数据块和数据节点的对应关系。
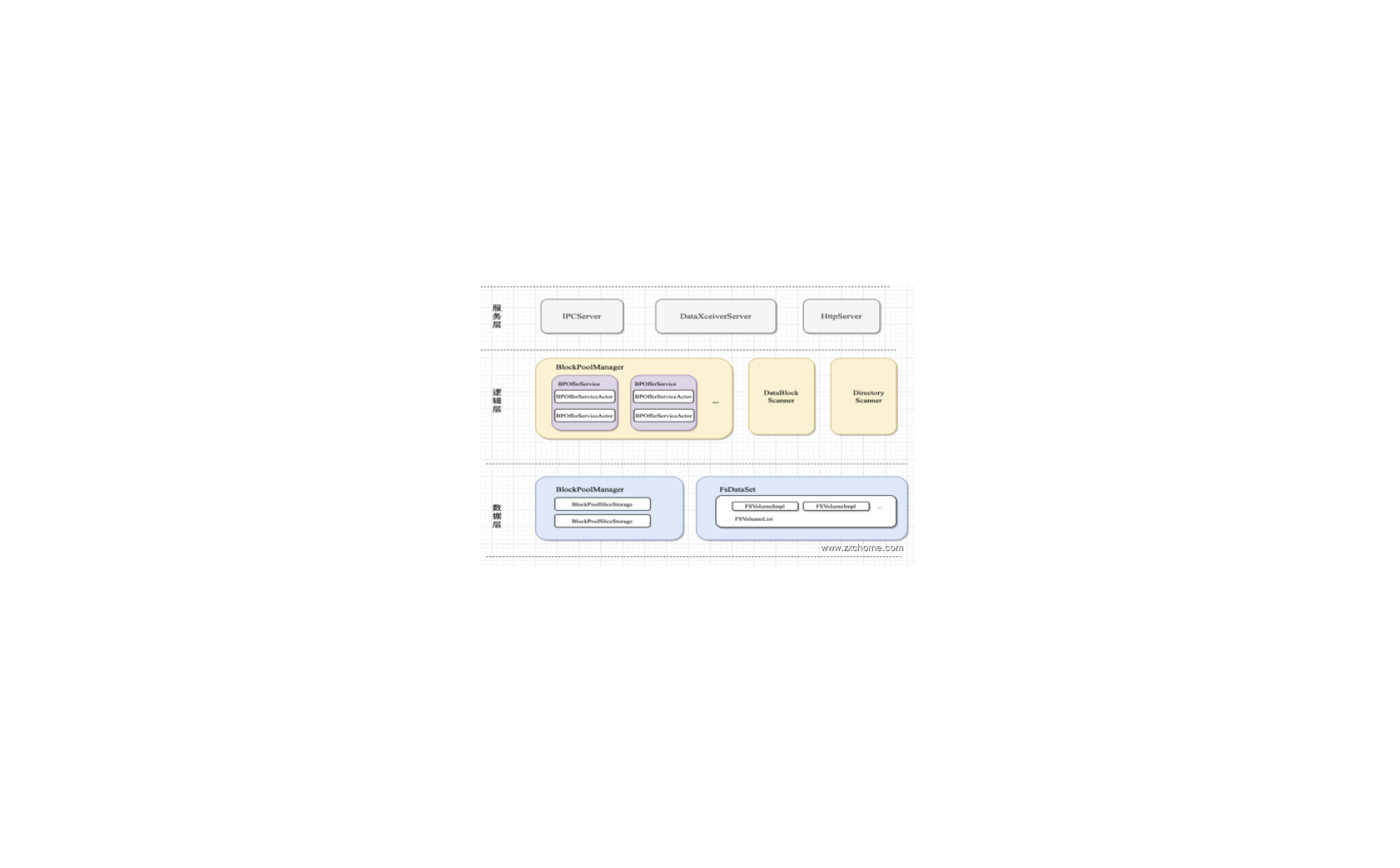
三、数据节点管理
Namenode 中会有很大一部分逻辑是与 Datanode 相关的,比如添加/删除 Datanode、处理 Datanode 发送的心跳等~
四、租约管理
租约是 Namenode 给予租约持有者(LeaseHolder,一般是 HDFS 客户端)在规定时间内拥有文件权限(写文件)的合同,Namenode 会执行租约的发放、回收、检查以及恢复等操作。
五、缓存管理
Hadoop 2.3.0 版本新增了集中式缓存管理功能(Centralized Cache Management),允许用户将一些文件和目录保存到 HDFS 缓存中。HDFS 的集中式缓存是由分布在 Datanode 上的堆外内存组成的,并且由 Namenode 统一管理。
 微信
微信 支付宝
支付宝