
Spark-理论笔记-RDD
RDD(Resilient Distributed Dataset) 叫着 弹性分布式数据集 ,是Spark 中最基本的抽象,它代表一个不可变、可分区、里面元素可以并行计算的集合。
特性
A list of partitions
一个分区(Partition)列表,组成了该 RDD 的数据。
这里表示一个 RDD 有很多分区,每一个分区内部是包含了该 RDD 的部分数据,spark 中任务是以 task 线程的方式运行, 一个分区就对应一个 task 线程。
用户可以在创建 RDD 时指定 RDD 的分区个数,如果没有指定,那么就会采用默认值。(比如: 读取HDFS上数据文件产生的RDD分区数跟block的个数相等)
A function for computing each split
Spark 中 RDD 的计算是以分区为单位的,RDD 的每个 partition 上面都会有计算函数
A list of dependencies on other RDDs
一个 RDD 会依赖于其他多个 RDD
RDD 与 RDD 之间的依赖关系,spark 任务的容错机制就是根据这个特性而来。
Optionally, a Partitioner for key-value RDDs
针对 key-value 类型的 RDD 才有分区函数,分区函数其实就是把计算的结果丢到不同的分区中。
当前 Spark 中实现了两种类型的分区函数
一个是基于哈希的 HashPartitioner
一个是基于范围的 RangePartitioner。
只有对于 key-value 的RDD,并且产生 shuffle,才会有 Partitioner,非 key-value 的 RDD 的 Parititioner 的值是None。
Optionally, a list of preferred locations to compute each split on
最优的位置去计算,也就是数据的本地性

spark任务在调度的时候会优先考虑存有数据的节点开启计算任务,减少数据的网络传输,提升计算效率。
数据在哪里,应优先把作业调度到数据所在机器上,减少数据的 IO 和网络传输,这样才能更好地减少作业运行时间
二、 RDD 弹性
2.1. 自动的进行内存和磁盘的存储切换
Spark会优先把数据放到内存中,如果内存实在放不下,会放到磁盘里面
RDD 持久化
RDD 的持久化由 Spark 的 Storage 模块负责,实现了 RDD 与物理存储的解耦合。
在对 RDD 持久化时,Spark 规定了 MEMORY_ONLY 、MEMORY_AND_DISK 等 7 种不同的存储级别, 存储级别是以下 5 个变量的组合:
| 存储级别 | 含义 |
|---|---|
| MEMORY_ONLY | 以非序列化的 Java 对象的方式持久化在 JVM 内存中。如果内存无法完全存储 RDD 所有的 partition,那么那些没有持久化的 partition 就会在下一次需要使用它们的时候,重新被计算 |
| MEMORY_AND_DISK | 同上,但是当 RDD 某些 partition 无法存储在内存中时,会持久化到磁盘中。下次需要使用这些 partition 时,需要从磁盘上读取 |
| MEMORY_ONLY_SER | 同 MEMORY_ONLY,但是会使用 Java 序列化方式,将 Java 对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大 CPU 开销 |
| MEMORY_AND_DISK_SER | 同 MEMORY_AND_DISK,但是使用序列化方式持久化 Java 对象 |
| DISK_ONLY | 使用非序列化 Java 对象的方式持久化,完全存储到磁盘上 |
| MEMORY_ONLY_2 MEMORY_AND_DISK_2 | 如果是尾部加了 2 的持久化级别,表示将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可 |
2.2. 基于Lineage 的容错机制
在容错机制中,如果一个节点死机了,而且窄依赖,则只要把丢失的父RDD分区重算即可,不依赖于其他节点。而宽依赖需要父RDD的所有分区都存在,重算就很昂贵了。可以这样理解开销的经济与否:在窄依赖中,在子RDD的分区丢失、重算父RDD分区时,父RDD相应分区的所有数据都是子RDD分区的数据,并不存在冗余计算。在宽依赖情况下,丢失一个子RDD分区重算的每个父RDD的每个分区的所有数据并不是都给丢失的子RDD分区用的,会有一部分数据相当于对应的是未丢失的子RDD分区中需要的数据,这样就会产生冗余计算开销,这也是宽依赖开销更大的原因。因此如果使用Checkpoint算子来做检查点,不仅要考虑Lineage是否足够长,也要考虑是否有宽依赖,对宽依赖加Checkpoint是最物有所值的。
2.3. Task 失败重试
task 如果失败会自动进行特定次数的重试,默认会自动重试4次。也可以在 spark-submit 的时候指定 spark.task.maxFailures 参数值
$Task$ 被调度到 $Executor$ 启动执行后,$Executor$ 会将执行状态上报给 $SchedulerBackend$, $SchedulerBackend$ 则通知该 $Task$ 对应的 $TaskSetManager$,对于失败的 $Task$,$TaskSetManager$ 会记录失败次数,如果失败次数还没有超过最大重试次数
2.4. stage 失败重试
stage 如果失败会自动进行特定次数的重试,而且只会计算失败的分片;
2.5. checkpoint 和 persist, 可主动或被动触发
Checkpoin和Persist都可以由我们自己来调用。checkpoint是对RDD进行标记,并且产生对应的一系列文件,且所有父依赖都会被删除,是整个Linage的终点。persist工作的主体RDD会把计算的分片结果保存在内存或磁盘上,以确保下次针对同一个RDD的调用可以重用。 两种的区别如下:
- Persist 将 RDD 缓存之后,其Linage关系任然存在,在节点宕机或RDD部分缓存丢失的时候,RDD任然可以根据Linage关系来重新运算;而 Checkpoint 将 RDD 写入到文件系统之后,将不再维护 Linage
- rdd.persist 即使调用的是 DISK_ONLY 操作,也就是只写入文件系统,该写入rdd是由BlockManager管理,executor程序停止后BlockManager也就停止了,所以其持久化到磁盘中的数据也会被清理掉;而checkpoint持久化到文件系统(HDFS文件或者是本地文件系统),不会被删除,还可以供其他程序调用
持久化的数据丢失的可能性更大,因为节点的故障会导致磁盘、内存的数据丢失。但是 checkpoint 的数据通常是保存在高可用的文件系统中,比如 HDFS 中,所以数据丢失可能性比较低
2.6. 数据调度弹性
DAGScheduler、TASKScheduler 和资源管理无关
DAGScheduler和TaskScheduler和资源无关。Spark将执行模型抽象为DAG,可以让多个Stage任务串联或者并行执行,而无需将中间结果写入到HDFS中。这样当某个节点故障的时候,可以由其他节点来执行出错的任务。
2.7. 数据分片的高度弹性
在计算的过程中,会产生很多的数据碎片,这时产生一个Partition可能会非常小,如果一个Partition非常小,每次都会消耗一个线程去处理,这时可能会降低它的处理效率,需要考虑把许多小的Partition合并成一个较大的Partition去处理,这样会提高效率。另外,有可能内存不是那么多,而每个Partition的数据Block比较大,这时需要考虑把Partition变成更小的数据分片,这样让Spark处理更多的批次,但是不会出现OOM。
三、RDD 的编程 API
3.1. Transformation
RDD 中的所有转换都是延迟加载的,也就是说,他们并不会直接就计算结果。相反的,他们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个返回结果的 Driver 的动作时,这些操作才会真正的运行
3.1.1. foreachPartition&foreach
原理类似于“使用mapPartitions替代map”,也是一次函数调用处理一个partition的所有数据,而不是一次函数调用处理一条数据。
3.1.2. mapPartitions&map
mapPartitions类的算子,一次函数调用会处理一个 partition 所有的数据,而不是一次函数调用处理一条,性能相对来说会高一些。但是有的时候,使用mapPartitions会出现OOM(内存溢出)的问题。因为单次函数调用就要处理掉一个partition所有的数据,如果内存不够,垃圾回收时是无法回收掉太多对象的,很可能出现OOM异常
3.1.3. repartitionAndSortWithinPartitions
repartitionAndSortWithinPartitions是Spark官网推荐的一个算子,官方建议,如果需要在repartition重分区之后,还要进行排序,建议直接使用repartitionAndSortWithinPartitions算子。因为该算子可以一边进行重分区的shuffle操作,一边进行排序。shuffle与sort两个操作同时进行,比先shuffle再sort来说,性能可能是要高的。
3.2. Action
触发代码的运行操作,一个Spark 应用,至少需要一个 Action 操作。
3.2.1. reduceByKey&groupByKey&aggregateByKey
groupByKey()
groupByKey实现了分组收集,即将相同的key的数据收集到一起,相同的key可能分布在多个节点上,所以需要把相同的key通过网络拉取到同一个节点才能收集。
是对 RDD 中的所有数据做 shuffle, 根据不同的 Key 映射到不同的 partition 中再进行aggregate。
groupByKey是一个效率很低的算子,因为它会导致数据在全网范围内的分发
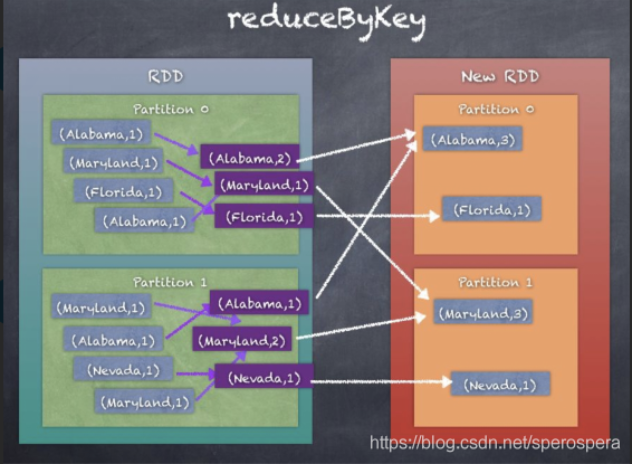
reduceByKey()
reduceByKey 与 groupByKey 相比,通过使用local combiner先做一次聚合运算,先在单台机器中计算,再将结果进行shuffle,减小运算量
reduceByKey会对value值进行聚合操作,且这种聚合操作首先在map端进行,聚合后的数据量会减少,相同key的结果会通过网络分发到同一个节点,然后进行最后一步的聚合。
aggregateByKey()
aggregateByKey 和reduceByKey类似,但更具灵活性,可以自定义在分区内和分区间的聚合操作,其比前二者更灵活,它可以为Map、Reduce阶段指定不同的聚合函数。
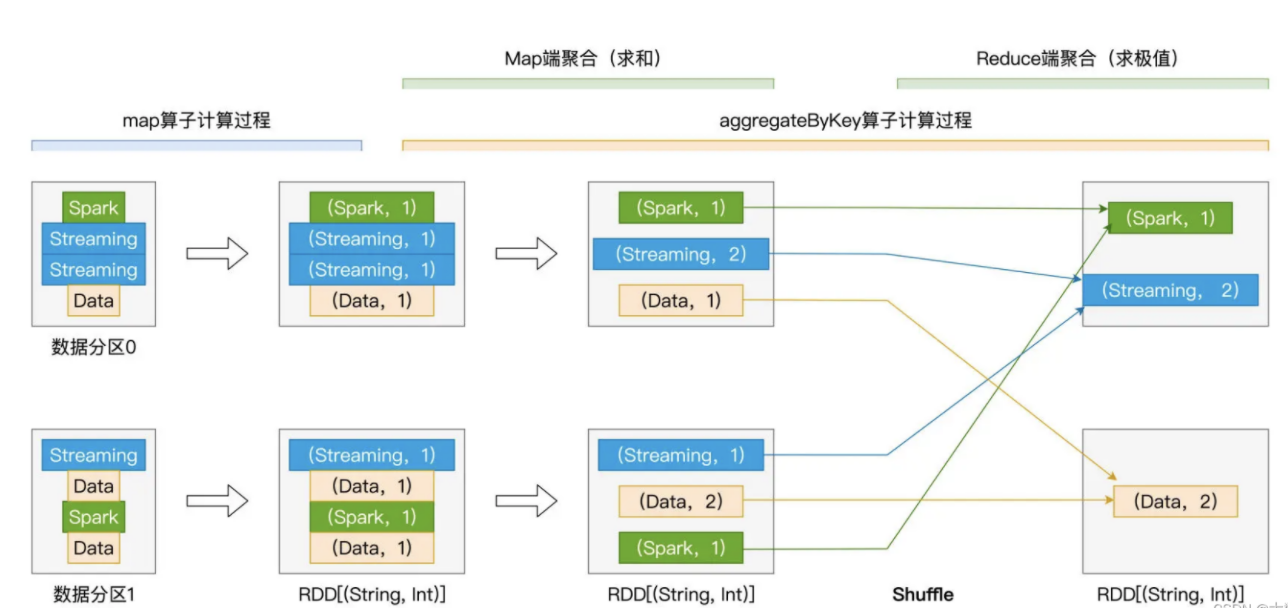
groupByKey、reduceByKey是在Map、Reduce端聚合函数相同的情况下的特殊的aggregateByKey操作。
sortByKey
sortByKey是对数据按key进行排序。这个算子也会导致数据在全网范围的分发,是一个效率比较低的算子。
3.2.2. $repartition$ & $coalesce$
两者都可以用于改变 $RDD$ 的 $partition$ 数量,$repartition$ 底层调用的就是 $coalesce$ 方法 $coalesce(numPartitions, shuffle = true)$
$repartition$ 一定会发生 $shuffle$,$coalesce$ 根据传入的参数来判断是否发生 $shuffle$。一般情况下增大 $RDD$ 的分区数量使用 $repartition$ 算子,减少分区数量时使用 $coalesce$ 算子。
rdd.coalesce方法,这个方法只能减少分区,不能增加分区,不会有shuffle的过程。
RDD 依赖关系
RDD 和它依赖的 父 RDD(可能有多个) 的关系有两种不同的类型,即 窄依赖(narrow dependency)和宽依赖(wide dependency)
窄依赖: 窄依赖指的是每一个父 RDD 的 Partition 最多被子 RDD 的一个分区使用
可以比喻为独生子女。
宽依赖: 宽依赖是多个子 RDD 的 Partition 会依赖同一个父 RDD 的 Partition
RDD Cache
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以序列化的形式缓存在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。

RDD CheckPoint
缓存和检查点的区别:
Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存储在 HDFS 等容错、高可用的文件系统,可靠性高。
建议对 checkpoint() 的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。
如果使用完了缓存,可以通过 unpersist()方法释放缓存
 微信
微信 支付宝
支付宝





