计算机基础-操作系统-文件的逻辑结构
“逻辑结构”,是指在用户看来,文件内部的数据应该是如何组织起来的。而“物理结构”指的是在操作系统看来,文件的数据是如何存放在外存中的。
类似于数据结构的 “逻辑结构” 和 “物理结构”,如 “线性表” 就是一种逻辑结构,在用户角度看来,线性表就是一组有先后关系的元素序列,如: a,b,c,d,e
“线性表” 这种 “逻辑结构” 可以用不同的物理结构实现,如: 顺序表/链表。顺序表的各个元素在逻辑上相邻,在物理上也相邻,链表的各个元素在物理上可以是不相邻的。因此,顺序表可以实现“随机访问”,而“链表”无法实现随机访问。
算法的具体实现与逻辑结构、物理结构都有关,文件也一样,文件操作的具体实现与文件的逻辑结构、物理结构都有关
按文件是否有结构分类,可以分为无结构文件、有结构文件两种。
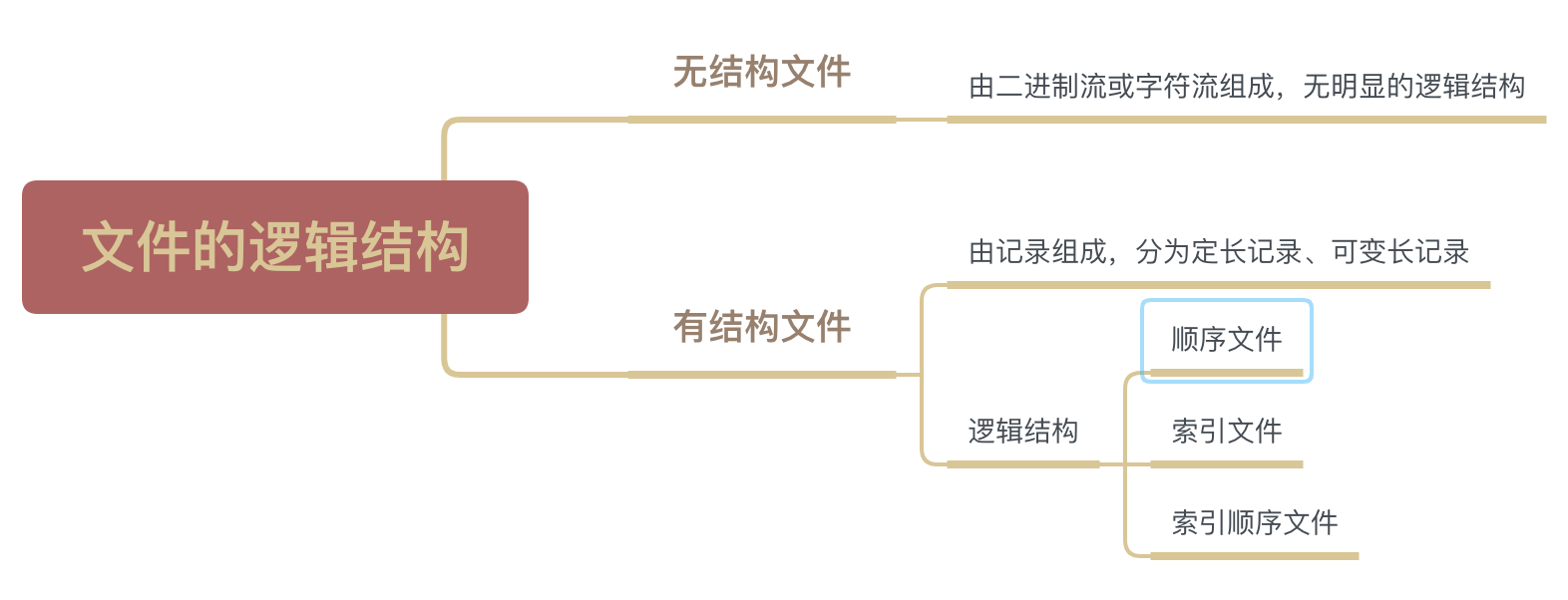
1. 无结构文件
文件内部的数据就是一系列二进制流或者字符流组成,又称为”流式文件”
Windows 中的
txt文件
2. 有结构文件
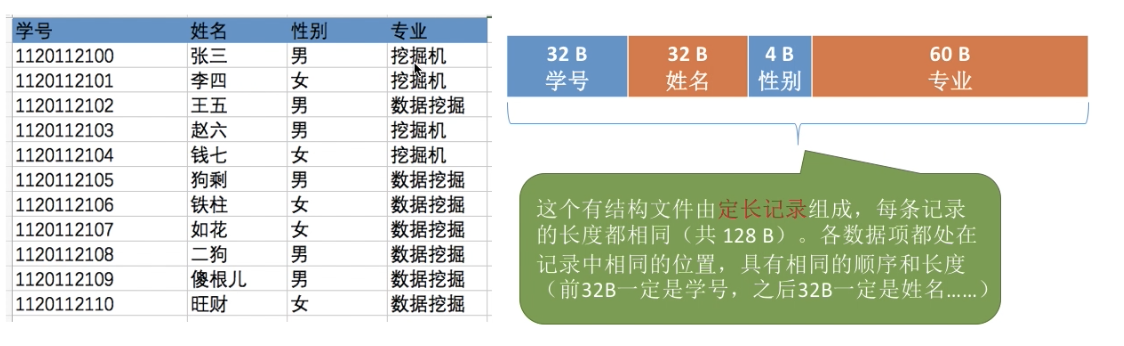
由一组相似的记录组成,又称 “记录式文件”。每条记录又若干个数据项组成。
如数据库表文件。
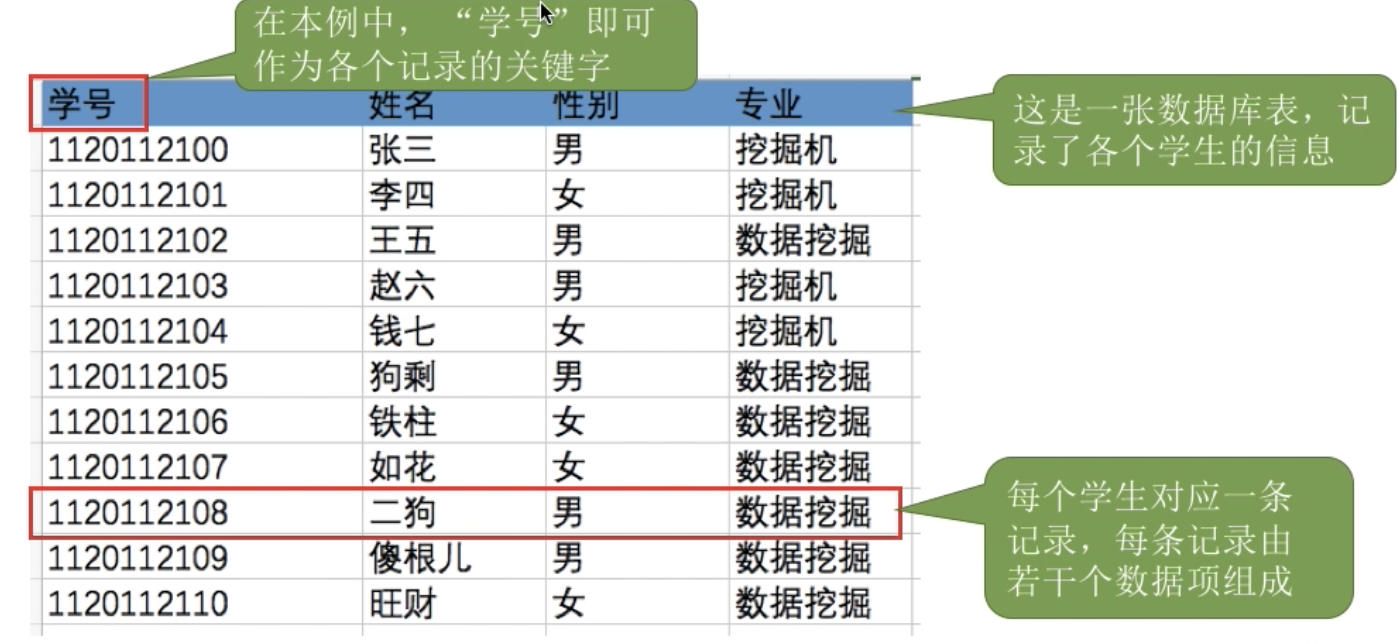
一般来说每条记录有一个数据项可作为关键字。
根据各条记录的长度(占用的存储空间)是否相等,又可分为定长记录和可变长记录两种。

2.1. 逻辑结构
根据有结构文件中的各条记录在逻辑上如何组织,可以分为三类:
2.1.1. 顺序文件
文件中的记录一个接一个地顺序排列(逻辑上),记录可以是定长的或可变长的。各个记录在物理上可以顺序存储或链式存储。


2.1.2. 索引文件
对于可变长记录文件,要找到第i个记录,必须先顺序第查找前11个记录,但是很多应用场景中又必须使用可变长记录
索引表本身是定长记录的顺序文件。因此可以快速找到第 i 个记录对应的索引项。可将关键字作为索引号内容,若按关键字顺序排列,则还可以支持按照关键字折半查找。
每当要增加/删除一个记录时,需要对索引表进行修改。由于索引文件有很快的检索速度,因此主要用于对信息处理的及时性要求比较高的场合
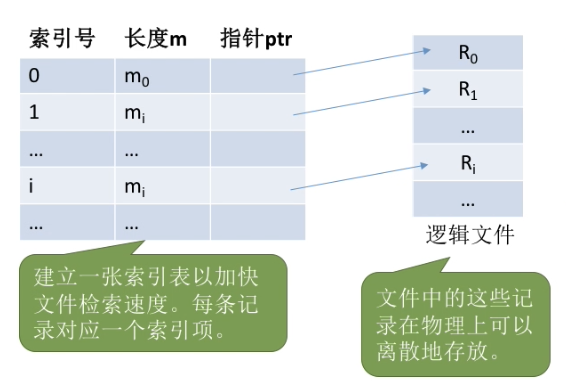
另外,可以用不同的数据项建立多个索引表。如: 学生信息表中,可用关键字 “学号” 建立一张索引表。也可用“姓名〞建立一张索引表。这样就可以根据“姓名”快速地检索文件了。
SQL 就支持根据某个数据项建立索引的功能
2.1.3. 索引顺序文件
思考索引文件的缺点: 每个记录对应一个索引表项,因此索引表可能会很大,例如文件的每个记录平均只占 8B,而每个索引表项占 32 个字节,那么索引表都要比文件内容本身大4倍,这样对存储空间的利用率就太低了。
索引顺序文件是索引文件和顺序文件思想的结合。索引顺序文件中,同样会为文件建立一张索引表,但不同的是: 并不是每个记录对应一个索引表项,而是一组记录对应一个索引表项。
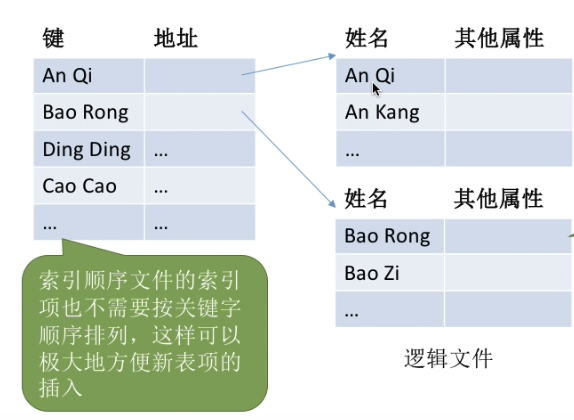
在本例中,学生记录按照学生姓名的开头字母进行分组。每个分组就是一个顺序文件,分组内的记录不需要按关键字排序
用这种策略确实可以让索引表“瘦身”,但是能否解决不定长记录的顺序文件检索速度慢的问题呢?
若一个顺序文件有10000个记录,则根据关键字检索文件,只能从头开始顺序查找(这里搞的并不是定长记录、顺序结构的顺序文件),平均须查找 5000个记录。
若采用索引顺序文件结构,可把 10000 个记录分为 100 组,每组 100 个记录。则需要先顺序查找索引表找到分组(共100个分组,因此索引表长度为100,平均需要查50次),找到分组后,再在分组中顺序查找记录(每个分组100 个记录,因比平均需要查50次)。可见,采用索引顺序文件结构后,平均查找次数减少为 50+50=100次。
若文件共有 $10^6$ 个记录,则可分为 1000 个分组,每个分组 1000 个记录。根据关键字检索一个记录平均需要查找500+500=1000 次。这个查找次数依然很多,如何解决呢?
2.1.4. 多级索引顺序文件
为了进一步提高检索效率,可以为顺序文件建立多级索引表。
例如,对于一个含 $10^6$ 个记录的文件,可先为该文件建立一张低级索引表,每 100 个记录为一组,故低级索引表中共有10000 个表项(即10000个定长记录),再把这 10000 个定长记录分组,每组100个,为其建立顶级索引表,故顶级索引表中有 100 个表项。

 微信
微信 支付宝
支付宝