Hadoop-组件-MapReduce-理论笔记-MapReduce 概述
MapReduce 1.x 的架构是主从架构。一个 JobTracker[主节点] 带多个 TaskTracker[从节点],从节点通过向主节点发送心跳信息来告诉它自己的运行情况,而主节点则是负责管理调度的工作。
1. 设计架构
1.1. Hadoop 1. x
MapReduce1 的架构是主从架构。一个 JobTracker[主节点] 带多个 TaskTracker[从节点],从节点通过向主节点发送心跳信息来汇报自己的健康情况和作业运行情况,而主节点则是负责管理调度的工作。
MapReduce 1.X 的架构如图所示,由 Client[客户端]、JobTracker[作业跟踪器]、TaskTracker[任务跟踪器]、Task[任务]组成。
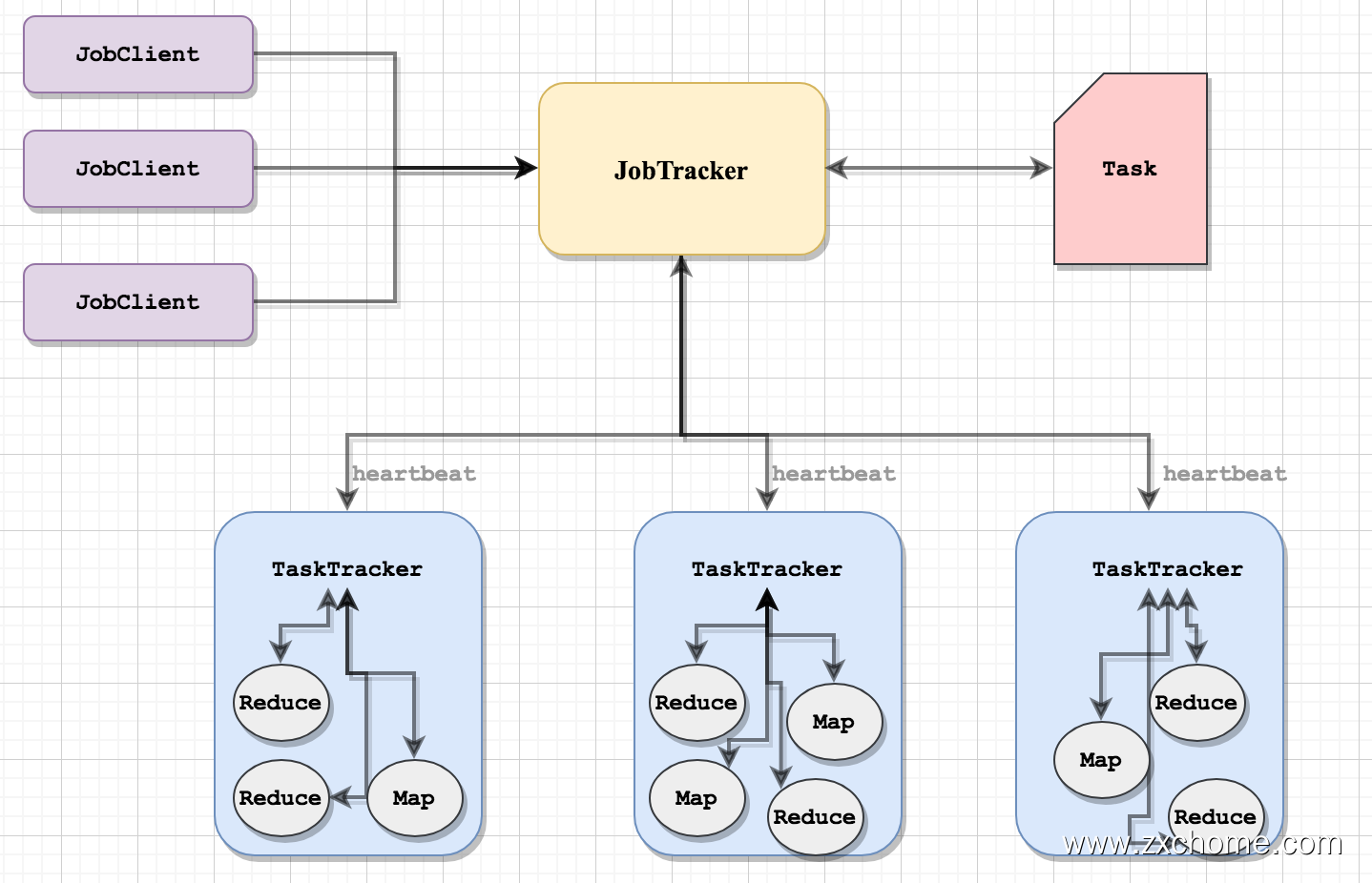
1.1.1. JobClient
用户编写的 MapReduce 程序通过 JobClient 提交给 JobTracker。
1.1.2. JobTracker
JobTracker 主要负责集群资源管理和作业调度,并且监控所有 TaskTracker 的健康情况,一旦有失败情况发生,就会将相应的任务分配到其他结点上去执行。
1.1.3. TaskTracker
TaskTracker 会周期性地通过“心跳”将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker 发送过来的命令并执行相应的操作(如启动新任务、杀死任务等) TaskTracker 使用“slot”等量划分本节点上的资源量(CPU、内存等)
Task 分为 Map Task 和 Reduce Task 两种,由 TaskTracker 启动,分别执行 Map 和 Reduce 任务。一般来讲,每个结点可以运行多个 Map 和 Reduce 任务。
1.2. Hadoop1.x 不足
Jobtracker 是 MapReduce 的集中处理点,存在单点故障
这两个系统的设计缺陷是单点故障,即 MR 的 JobTracker 和 HDFS 的 NameNode 两个核心服务均存在单点问题,该问题在很长时间内没有解决,这使得 Hadoop 在相当长时间内仅适合离线存储和离线计算。
针对Hadoop1.0单NameNode制约HDFS的扩展性问题,提出HDFS Federation,它让多个NameNode分管不同的目录进而实现访问隔离和横向扩展,同时彻底解决了NameNode单点故障问题
小文件存档
无法高效的对大量小文件进行存储。
存储大量小文件的话,它会占用NamelNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的在hadoop2.x的时候更新了新特性
HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。
这个新特性在一定程度上解决了hdfs存储小文件的问题,但是仍然不建议在hdfs中存储大量小文件.
JobTracker 既负责资源管理又负责作业调度,当作业增多时,JobTracker 内存是扩展的瓶颈
Hadoop2.0将JobTracker中的资源管理和作业调度分开,分别由ResourceManager(负责所有应用程序的资源分配)和ApplicationMaster(负责管理一个应用程序)实现,即引入了资源管理框架Yarn。
Yarn作为Hadoop2.0中的资源管理系统,它是一个通用的资源管理模块,可为各类应用程序进行资源管理和调度,不仅限于MapReduce一种框架,也可以为其他框架使用,如Tez、Spark、Storm等
在mapreduce的架构设计上,hadoop1.x中mapreduce兼具计算和资源调度两个作用,而在hadoop2.x中则将mapreduce中的资源调度功能剥离形成一个独立的框架叫做yarn。使得hadoop更加地灵活,因为剥离后的yarn不仅可以运行在hadoop平台,也可以运行在其他的平台,如spark。
在 TaskTracker 端,以 Map/Reduce task 的数目作为资源的表示过于简单,没有考虑到 CPU / 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM
Map task 全部完成后才能执行 Reduce task,造成资源空闲浪费
1.3. Hadoop2.x
Hadoop2.0 之后,MapReduce 可以理解为是一个 jar 包或一个程序,这个程序要运行在 Yarn 上面,上面有两个进程,ResourceManager 和 NodeManager
ResourceManager里面有两个模块
- Application Manager 应用程序管理器
- Scheduler 调度器
NodeManager 相当于执行一个容器,这个容器里面有 CPU+Memory,这个容器运行一个封装的任务,MapTask 或者ReduceTask
2. 工作机制
2.1. 切片机制
对于 HDFS 中存储的一个文件,要进行 Map 处理前,需要将它切分成多个片,才能分配给不同的 MapTask 去执行。 分片的数量等于启动的 MapTask 的数量。默认情况下,分片的大小就是 HDFS 的 blockSize。
2.1.1. 流程
找到数据存储的目录。
开始遍历处理目录下的每一个文件
遍历第一个文件 word.txt
获取文件大小 fs.sizeOf(word.txt)
计算切片大小
computeSliteSize(Math.max(minSize, Math.min(maxSize,blocksize)))
默认情况下,切片大小 = blocksize
开始切
第 1个切片:word.txt—0:128M
第 2个切片:word.txt—128:256M
第 3个切片:word.txt—256M:300M
每次切片时,都要判断切完剩下的部分是否大于块的1.1倍,不大于1.1倍就划分一块切片
将切片信息写到一个切片规划文件中
数据切片只是在逻辑上对输入数据进行分片,并不会再磁盘上将其切分成分片进行存储。InputSplit只记录了分片的元数据信息,比如起始位置、长度以及所在的节点列表等。
注意:block 是 HDFS 上物理上存储的存储的数据,切片是对数据逻辑上的划分。
2.2. Combiner 机制
Combiner 是一个本地化的 reduce 操作,它是 Map 运算的后续操作,Hadoop 允许用户针对 Map task 的输出指定一个合并函数, 减少传输到 Reduce 中的数据量, 削减 Mapper 的输出从而减少网络带宽和 Reducer 之上的负载。
2.2.1. 性能瓶颈
- 如果我们有10亿个数据,Mapper 会生成10亿个键值对在网络间进行传输,但如果我们只是对数据求最大值,那么很明显的Mapper 只需要输出它所知道的最大值即可。这样做不仅可以减轻网络压力,同样也可以大幅度提高程序效率。
- 使用专利中的国家一项来阐述数据倾斜这个定义。这样的数据远远不是一致性的或者说平衡分布的,由于大多数专利的国家都属于美国,这样不仅 Mapper 中的键值对、中间阶段(shuffle)的键值对等,大多数的键值对最终会聚集于一个单一的Reducer 之上,压倒这个 Reducer,从而大大降低程序的性能。
2.2.2. 使用场景
并不是所有的 Job 都适用 Combiner,只有操作满足结合律的才可设置 Combiner。
Combiner 操作类似于: opt(opt(1, 2, 3), opt(4, 5, 6))。如果 opt 为求和、求最大值的话,可以使用,但是如果是求中值或平均值的话,不适用。
2.3. 分区器
Partitioner 组件可以对 MapTask 后的数据按 Key 进行分区,从而将不同分区的 Key 交由不同的 Reduce 处理 收集阶段
在用户编写 map() 函数中,当数据处理完成后,一般会调用 OutputCollector.collect() 输出结果。在该函数内部,它会将生成的 key/value 分区[调用Partitioner],并写入一个环形内存缓冲区中。
 微信
微信 支付宝
支付宝