
Spark-源码学习-SparkSQL-架构设计-SQL 引擎-数据结构-TreeNode 体系
一、概述
无论是逻辑计划还是物理计划,都离不开中间数据结构。在 Catalyst 中,对应的是 TreeNode 体系。TreeNode 类是 SparkSQL 中所有树结构的基类,定义了一系列通用的集合操作和树遍历操作接口。
二、实现
2.1. 属性
TreeNode 内部包含一个 Seq[BaseType] 类型的变量 children 来表示孩子节点。TreeNode 定义了 foreach、 map、collect 等针对节点操作的方法,以及 transformUp 和 transformDown 等遍历节点并对匹配节点进行相应转换的方法。TreeNode 本身是 scala.Product 类型,因此可以通过 productElement 函数或 productlterator 迭代器对 Case Class 参数信息进行素引和遍历。
TreeNode 一直在内存里维护,不会 dump 到磁盘以文件形式存储,且无论在映射逻辑执行计划阶段,还是优化逻辑执行计划阶段,树的修改都是以替换己有节点的方式进行的。
作为基础类,TreeNode 本身仅提供了最简单和最基本的操作。 TreeNode 中现有的一些方法,例如不同遍历方式的 transform 系列方法、用于替换新的子节点的 withNewChildren 方法等。此外,treeString 函数能够将 TreeNode 以树型结构展示,在查看表达式、逻辑算子树和物理算子树时经常用到。
2.1.1. origin
1 | val origin: Origin = CurrentOrigin.get |
Catalyst 提供了节点位置功能,即能够根据 TreeNode 定位到对应的 SQL 字符串中的行数和起始位置。该功能在 SQL解析发生异常时能够方便用户迅速找到出错的地方。
Origin 提供了 line 和 startPosition 两个构造参数,分别代表行号和偏移量。在 CurrentOrigin 对象中,提供了各种 set 和 get 操作。其中,比较重要的是 withOrigin 方法,支持在 TreeNode 上执行操作的同时修改当前 origin 信息。
CurrentOrigin
CurrentOrigin 为 TreeNodes 提供一个可以查找上下文的地方,比如当前正在解析哪行 code。

2.1.2. Origin
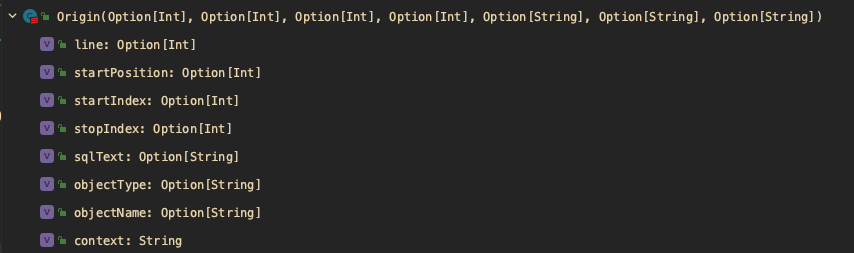
2.1.3. ineffectiveRules
用于记录此 TreeNode 及其子树的无效规则 ID 的 BitSet,
1 | /** |
将规则 ID 的缓存 BitSet 嵌入到每个树/表达式节点T中,可以跟踪规则 R 对于根植于 T 的子树是有效还是无效。这样,如果 R 在 T 上被调用,并且已知 R 无效,如果 R 再次应用于 T (例如,R 位于定点规则批处理中),可以跳过它。
$markRuleAsIneffective()$
标记 id 为 ruleId 的规则对此 TreeNode 及其子树无效。
1
2
3
4
5
6protected def markRuleAsIneffective(ruleId : RuleId): Unit = {
if (ruleId eq UnknownRuleId) {
return
}
ineffectiveRules.set(ruleId.id)
}$isRuleIneffective()$
对于 id = ruleId 的规则,此 TreeNode 及其子树是否已被标记为无效,如果该规则已被标记为无效,返回 true; 否则为 false 。如果 ruleId 是 UnknownId,则返回 false。
1
2
3
4
5
6protected def isRuleIneffective(ruleId : RuleId): Boolean = {
if (ruleId eq UnknownRuleId) {
return false
}
ineffectiveRules.get(ruleId.id)
}
2.1.4. nodePatterns
1 | /** |
Databricks 内部基准测试表明,对于 TPC-DS 查询,每个查询平均调用树转换函数约280k次,因此 Spark 在每个树节点中嵌入 BitSet,以传递自身及其子树的信息,并利用计划不变性来修剪不必要的遍历。在 TreeNode 增加 nodePatterns 属性,所有继承该类的节点可以通过复写该属性值来标识自己的属性。
TreePattern 是一个枚举类型, 对于每个节点/表达式都可以为其设置一个 TreePattern 方便标识
2.1.5. treePatternBits
1 | /** |
$getDefaultTreePatternBits()$
1
2
3
4
5
6
7
8
9
10
11
12
13
14protected def getDefaultTreePatternBits: BitSet = {
val bits: BitSet = new BitSet(TreePattern.maxId)
// Propagate node pattern bits
val nodePatternIterator = nodePatterns.iterator
while (nodePatternIterator.hasNext) {
bits.set(nodePatternIterator.next().id)
}
// Propagate children's pattern bits
val childIterator = children.iterator
while (childIterator.hasNext) {
bits.union(childIterator.next().treePatternBits)
}
bits
}- BitSet
2.1.6. tags
用于保存该树节点的辅助信息。可以通过 $makeCopy()$ 方法复制该节点 tag 或通过 $transformUp()/transformDown()$ 转换该节点 tag。
1 | private val tags: mutable.Map[TreeNodeTag[_], Any] = mutable.Map.empty |
2.2. 方法
$children$
返回该节点的 seq of children,children 是不可变的。有三种情况:
LeafNode: 无 children
UnaryNode: 包含一个 child
BinaryNode: 包含 left、right 两个 child
$transformDown$
1
2
3def transformDown(rule: PartialFunction[BaseType, BaseType]): BaseType = {
transformDownWithPruning(AlwaysProcess.fn, UnknownRuleId)(rule)
}$transformUp$
和 $transformDown()$ 逻辑基本一致
$transformDownWithPruning$
将规则ID的缓存BitSet嵌入到每个树/表达式节点T中,这样我们就可以跟踪规则R对于根植于T的子树是有效还是无效。这样,如果R在T上被调用,并且已知R无效,如果R再次应用于T(例如,R位于定点规则批处理中),我们可以跳过它。这个想法最初被用于Cascades optimizer,以加快探索性规划。
- 参数
- cond: TreePatternBits => Boolean: 判断是否存在可优化的节点,由规则设计者所提供
- ruleId: 不会生效的规则ID,自动更新
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26def transformDownWithPruning(cond: TreePatternBits => Boolean, ruleId: RuleId = UnknownRuleId)(rule: PartialFunction[BaseType, BaseType])
: BaseType = {
if (!cond.apply(this) || isRuleIneffective(ruleId)) {
return this
}
// 执行 rule 的逻辑
val afterRule = CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(this, identity[BaseType])
}
if (this fastEquals afterRule) {
// 如果应用了 rule 后节点无变化,则递归将 rule 应用于 children
val rewritten_plan = mapChildren(_.transformDownWithPruning(cond, ruleId)(rule))
// 递归应用 rule 后节点无变化
if (this eq rewritten_plan) {
// 标记 id 为 ruleId 的规则对此 TreeNode 及其子树无效。
markRuleAsIneffective(ruleId)
this
} else {
rewritten_plan
}
} else {
// If the transform function replaces this node with a new one, carry over the tags.
afterRule.copyTagsFrom(this)
afterRule.mapChildren(_.transformDownWithPruning(cond, ruleId)(rule))
}
}- 参数
$multiTransformDown() / multiTransformDownWithPruning()$
$withNewChildren$
使用 new children 替换并返回该节点的拷贝。该方法会对 productElement 每个元素进行模式匹配,根据节点类型及一定规则进行替换。
$mapChildren$
返回
f应用于所有子节点后该节点的 copy。其内部的原理是调用 $mapProductIterator$ ,对每一个productElement(i)进行各种模式匹配,若能匹配上某个再根据一定规则进行转换
三、继承体系
TreeNode 提供的是一种泛型,包含了两个子类继承体系,QueryPlan 和 Expression 体系。

3.1. Expression
Expression 是 Catalyst 中的表达式体系,Catalyst 实现了完善的表达式体系,在 Spark SQL 中,Expression 本身也是 TreeNode 类的子类,因此能够调用所有 TreeNode 的方法,例如 $transform()$ 等,也可以通过多级的子 Expression 组合成复杂的 Expression。
Expression 一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运算、逻辑操作、转换操作、过滤操作等。
3.2. QueryPlan
QueryPlan 类包含逻辑算子树(LogicalPlan)和物理执行算子树(SparkPlan) 两个重要的子类,其中逻辑算子树在 Catalyst 中内置实现,可以剥离出来直接应用到其他系统中;而物理算子树 SparkPlan 和 Spark 执行层紧密相关,当 Catalyst 应用到其他计算模型时,可以进行相应的适配修改。
3.2.1. 模块
QueryPlan 的主要操作分为6个模块,分别是输入输出、字符串、规范化、表达式操作、基本属性和约束。下面简单介绍这6 个模块。
输入输出
QueryPlan 的输入输出定义了 5 个方法,其中 output 是返回值为 Seq[Attribute]的虚函数,具体内容由不同子节点实现,而 outputSet 是将 output 的返回值进行封装,得到 AttributeSet 集合类型的结果。获取输入属性的方法 inputSet 的返回值也是 AttributeSet,节点的输入属性对应所有子节点的输出;producedAttributes 表示该节点所产生的属性;
missingInput 表示该节点表达式中涉及的但是其子节点输出中并不包含的属性。
基本属性
表示 QueryPlan 节点中的一些基本信息
- schema 对应 output 输出属性的 schema 信息
- allAttributes 记录节点所涉及的所有属性(Attribute)列表
- aliasMap 记录节点与子节点表达式中所有的别名信息
- references 表示节点表达式中所涉及的所有属性集合
- subqueries 和 innerChildren 都默认实现该 QueryPlan 节点中包含的所有子查询。
字符串
主要用于输出打印 QueryPlan 树型结构信息,其中 schema 信息也会以树状展示。
需要注意的一个方法是 statePrefx(),用来表示节点对应计划状态的前缀字符
缓存查询计划
$QueryPlan.sameResult$ 通过比较两个查询计划的
canonicalized是否相等来决定是否启用缓存1
final def sameResult(other: PlanType): Boolean = this.canonicalized == other.canonicalized
canonicalized到底是什么呢🤔️~实现同一种功能,不同开发人员使用的 SQL 语法都可能存在差异,此时,为了保证能够充分利用到已有的查询计划,需要针对不同的查询计划做一个
规范化的处理,这就是canonicalized存在的意义~1
2
3
4
5
6
7
8final lazy val canonicalized: PlanType = {
var plan = doCanonicalize()
if (plan eq this) {
plan = plan.makeCopy(plan.mapProductIterator(x => x.asInstanceOf[AnyRef]))
}
plan._isCanonicalizedPlan = true
plan
}$doCanonicalize$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16protected def doCanonicalize(): PlanType = {
val canonicalizedChildren = children.map(_.canonicalized)
var id = -1
mapExpressions {
case a: Alias =>
id += 1
val normalizedChild = QueryPlan.normalizeExpressions(a.child, allAttributes)
Alias(normalizedChild, "")(ExprId(id), a.qualifier)
case ar: AttributeReference if allAttributes.indexOf(ar.exprId) == -1 =>
id += 1
ar.withExprId(ExprId(id)).canonicalized
case other => QueryPlan.normalizeExpressions(other, allAttributes)
}.withNewChildren(canonicalizedChildren)
}
 微信
微信 支付宝
支付宝








