
Spark-源码学习-SparkSQL-HelloAQE
一、概述
在 Spark 3.0 引入了自适应查询执行(Adaptive Query Execution,AQE) 框架,AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化。
首先,AQE 赖以优化的统计信息与 CBO 不同,这些统计信息并不是关于某张表或是哪个列,而是 Shuffle Map 阶段输出的中间文件,每个 Map Task 都会输出以 data 为后缀的数据文件,还有以 index 为结尾的索引文件,这些文件统称为中间文件。每个 data 文件的大小、空文件数量与占比、每个 Reduce Task 对应的分区大小,所有这些基于中间文件的统计值构成了 AQE 进行优化的信息来源。
其次,AQE 从运行时获取统计信息,在条件允许的情况下,优化决策会分别作用到逻辑计划和物理计划。
Spark AQE,总体思想是动态优化和修改 stage 的物理执行计划。利用执行结束的上游 stage 的统计信息(主要是数据量和记录数),来优化下游 stage 的物理执行计划。
1.1. RBO&CBO
CBO(Cost Based Optimization,基于成本的优化)
CBO 是一种基于数据统计信息例如数据量、数据分布来选择代价最小的优化策略的方式。
RBO(Rule Based Optimization,基于规则的优化)
RBO 基于一些规则和策略实现,如谓词下推、列剪枝,这些规则和策略来源于数据库领域已有的应用经验。也就是说,启发式的优化实际上算是一种「经验主义」
RBO 相对于 CBO 而言要成熟得多,常用的规则都基于经验制定,可以覆盖大部分查询场景,并且方便扩展。其缺点则是不够灵活,对待相似的问题和场景都使用同一类解决方案,忽略了数据本身的信息。
1.2. 触发时机
那么它是怎么实现基于统计信息修改尚未执行的逻辑计划和物理计划的呢?
在非 AQE 的情况下,Spark 会在规划阶段确定了物理执行计划后,根据每个算子的定义生成 RDD 对应的 DAG。然后 Spark DAGScheduler 通过 shuffle 来划分 RDD Graph 并创建 stage,然后提交 Stage 以供执行。

结合 Spark SQL 端到端优化流程图我们可以看到,AQE 从运行时获取统计信息,在条件允许的情况下,优化决策会分别作用到逻辑计划和物理计划。
二、AQE 特性
AQE 根据 Map 阶段的统计信息以及优化规则与策略,来动态地调整和修正尚未执行的逻辑计划和物理计划,这就是 AQE 的三大特性: Join 策略调整、自动分区合并,以及自动倾斜处理。
3.1. Join 策略调整
如果某张表在过滤之后,尺寸小于广播变量阈值,这张表参与的数据关联就会从 Shuffle Sort Merge Join 降级为执行效率更高的 Broadcast Hash Join。
3.1.1. Spark Join 策略
Spark 支持的许多 Join 策略中,Broadcast Hash Join 通常是性能最好的,前提是参加 join 的一张表的数据能够装入内存。由于这个原因,当 Spark 估计参加 join 的表数据量小于广播大小的阈值时,其会将 Join 策略调整为 Broadcast Hash Join。但是,很多情况都可能导致这种大小估计出错——例如存在一个非常有选择性的过滤器。
3.1.2. 策略调整
每当 DAG 中的 Map 阶段执行完毕,Spark SQL 就会结合 Shuffle 中间文件的统计信息,重新计算 Reduce 阶段数据表的存储大小。如果发现基表尺寸小于广播阈值, 那么 Spark SQL 就把下一阶段的 Shuffle Join 调整为 Broadcast Join。
3.1.3. 相关规则
- OptimizeShuffleWithLocalRead
- DynamicJoinSelection
3.2. 自动分区合并
3.2.1. 概述
在 Reduce 阶段,当 Reduce Task 从全网把数据分片拉回,AQE 按照分区编号的顺序,依次把小于目标尺寸的分区合并在一起。
在 Shuffle 中,Partition 的数量十分关键。Partition 的最佳数量取决于数据,而数据大小在不同的 query 不同 stage 都会有很大的差异,所以很难去确定一个具体的数目。在这部分,有两个非常重要的参数用来控制目标分区的大小:
- spark.sql.adaptive.advisoryPartitionSizeInBytes: 分区合并后的推荐尺寸
- spark.sql.adaptive.coalescePartitions.minPartitionNum: 分区合并后最小分区数
为了解决该问题,在最开始设置相对较大的 shuffle partition 个数,通过执行过程中 shuffle 文件的数据来合并相邻的小 partitions。
例如,假设我们执行SELECT max(i) FROM table GROUP BY j,表table只有2个partition并且数据量非常小。我们将初始shuffle partition设为5,因此在分组后会出现5个partitions。若不进行AQE优化,会产生5个tasks来做聚合结果,事实上有3个partitions数据量是非常小的。
这种情况下,AQE生效后只会生成3个reduce task。
3.2.2. 规则: CoalesceShufflePartitions
在 Shuffle Map 阶段完成之后,AQE 优化机制被触发,CoalesceShufflePartitions 策略地被添加到新的物理计划中。读取配置项、计算目标分区大小、依序合并相邻分区这些计算逻辑,在 Tungsten WSCG 的作用下融合进“手写代码”于 Reduce 阶段执行。
3.3. 自动倾斜处理
3.3.1. 概述
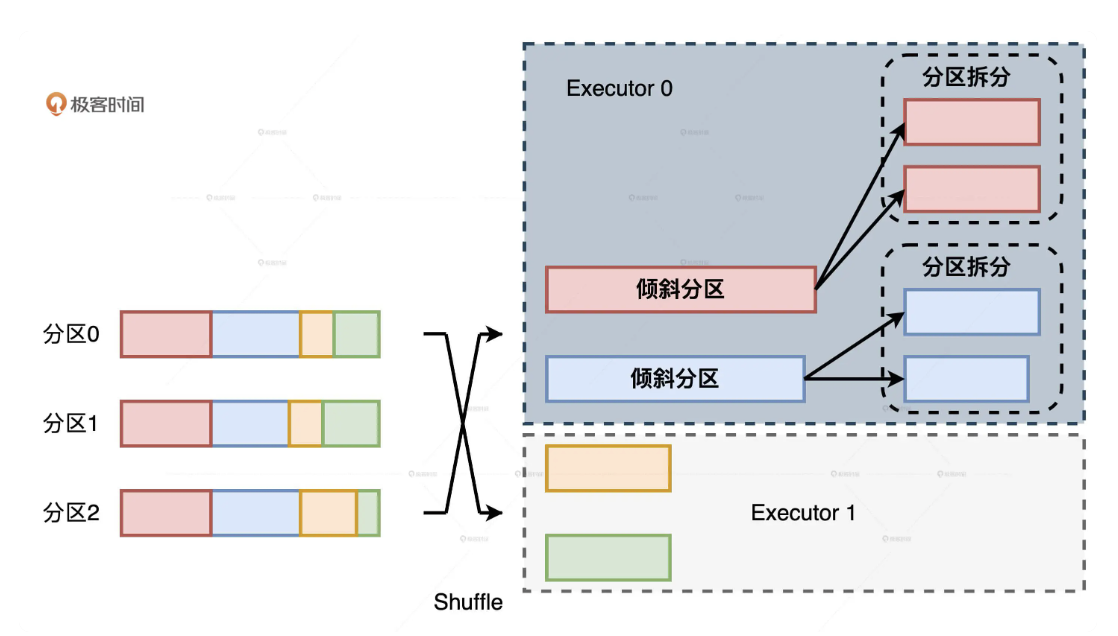
AQE 根据 shuffle 文件统计数据自动检测倾斜数据,将那些倾斜的分区打散成小的子分区,然后各自进行 Join。
我们可以看下这个场景,Table A join Table B,其中Table A的partition A0数据远大于其他分区。AQE 会将 partition A0 切分成2个子分区,并且让他们独自和Table B 的 partition B0 进行 join。如果不做这个优化,SMJ 将会产生 4 个 tasks 并且其中一个执行时间远大于其他。经优化,这个 join 将会有 5 个 tasks,但每个 task 执行耗时差不多相同,因此个整个查询带来了更好的性能。
关于如何定位这些倾斜的分区,主要靠下面三个参数:
- spark.sql.adaptive.skewJoin.skewedPartitionFacto: 判定倾斜的倾斜因子
- spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes: 判定倾斜的最低阈值
- spark.sql.adaptive.advisoryPartitionSizeInBytes: 倾斜数据分区拆分,小数据分区合并优化时,建议的分区大小(以字节为单位)
3.3.2. 相关规则: OptimizeSkewedJoin
与自动分区合并相反,自动倾斜处理的操作是”拆”: 在 Reduce 阶段,当 Reduce Task 所需处理的分区尺寸大于一定阈值时,利用 OptimizeSkewedJoin 策略,AQE 会把大分区拆成多个小分区,降低单个 Reduce Task 的工作负载。
三、实现
2.1. InsertAdaptiveSparkPlan
InsertAdaptiveSparkPlan 物理优化 Rule, 它是 AQE 开启的入口。 SparkSQL 从逻辑计划转换为物理计划后,并不能直接被执行,还需要经过preparations 阶段。InsertAdaptiveSparkPlan 优化 Rule 就是被调用在 QueryExecution.preparations 中。
并不是所有的任务都可以使用 AQE,只有存在 Shuffle 的 SparkSQL 任务才会有可能使用到 AQE。但开启 AQE 也并不是那么容易。
- 判断是否开启 AQE
- 首先和数据写入相关的命令算子不会应用 AQE
- 其次判断是否满足以下条件之一可以应用 AQE
- 验证是否支持 AQE
2.2. 物理执行算子 AdaptiveSparkPlanExec
既然它是物理计划执行算子,那么其方法 $doExecute()$
可以看出其调用了 $withFinalPlanUpdate$ 来获取最终的物理计划的更新,然后在 $withFinalPlanUpdate$ 中又调用 $getFinalPhysicalPlan()$ 获取最终的物理计划。
在 $getFinalPhysicalPlan$ 会将currentPhysicalPlan传给createQueryStages方法,这个方法的输出类型是CreateStageResult,这个方法会从下到上递归的遍历物理计划树生成新的Query stage,这个 createQueryStages 方法在每次计划发生变化时都会被调用。
createQueryStages 会从下到上遍历并应用物理计划树的所有节点,根据节点的类型不同其处理也是不同的:
- 对于 Exchange 类型的节点,exchange 会被 QueryStageExec 节点替代。如果开启了 stageCache,同时 exchange 节点是存在的 stage, 则直接重用 stage 作为QueryStage, 并封装返回 CreateStageResult。否则,从下向上迭代,如果孩子节点都迭代完成,将基于 broadcast 转换为 BroadcastQueryStageExec,shuffle 作为ShuffleQueryStageExec,并将其依次封装为 CreateStageResult。
- 对于 QueryStageExec 节点类型,直接封装为 CreateStageResult 返回。
- 对于其余类型,createQueryStages 函数应用于节点的直接子节点,这当然会导致再次调用 createQueryStages 并创建其他 QueryStageExec。
三、总结
3.1. 主要流程
首先,SparkSQL 经过 Catalyst 转换为逻辑计划或物理计划树。
AQE 开启后,AdaptiveSparkPlanExec 被执行时,它会调用 $getFinalPhysicalPlan()$ 方法来启动执行流程。通过递归的自下而上的调用 $createQueryStages()$ 方法,将 plan 树转换为包含 QueryStageExec 的树,主要是将 broadcast 和 shuffle 转换为其对应的 QueryStageExec,它将实现其输出,物化输出的数据统计信息可用于优化后续的查询阶段。在第一次转换之后,算法会记住所有新的和未解决的 QueryStage,这些阶段稍后会提交以进行物理执行。在 $newQueryStage()$ 中会调用 AQE 物理计划层面的优化规则。
然后,将当前的逻辑计划中所有的 query stages 替换为 LogicalQueryStage。转换后的逻辑计划有新的统计数据可用,再调用其 $reOptimize()$ 方法这可能会产生一个全新的、基于实用的逻辑计划和物理计划。并比较新旧计划的成本,如果新的优化计划比前一个更优化,则将其提升为新的 currentPhysicalPlan 和 currentLogicalPlan。一旦执行了所有查询阶段,就会生成最终的物理计划。在reOptimize方法中会调用AQE逻辑层面的优化规则。
3.2. Refer
https://mp.weixin.qq.com/s/6wzYqg5gmhE3FrIxmldtzw
 微信
微信 支付宝
支付宝








